
Making the EIA Short-Term Energy Outlook Searchable with Databricks Document Intelligence

I have been building RAG systems in both development and production settings since the GPT-3 API became generally available in the winter of 2021. I remember being blown away by the tech, but immediately frustrated: how do I give it access to my own data? I spent a lot of time confused about when to use RAG versus fine-tuning. Fast forward to 2026 and RAG has come a long way, but it is still genuinely hard to get right, and keeping up with the pace of change is its own challenge.
I have been continuing to enjoy exploring energy market data in my spare time and bring various datasets into my Databricks environment for analysis. I have pipelines pulling in ERCOT data (real-time load actuals, hub settlement prices, and historical 4CP peaks), EIA petroleum and natural gas storage inventories, crude oil and natural gas production figures from the Drilling Productivity Report, commodity price history for WTI, Brent, Henry Hub, RBOB, and heating oil via Yahoo Finance, weather data for six Texas cities tied to ERCOT load zones, energy news headlines with AI-driven sentiment and commodity tagging, and growing.
With this ever-growing dataset and with Databricks releasing a new AI function, I thought there would be no better dataset to test on than the Short-Term Energy Outlook (STEO) from the U.S. Energy Information Administration. Every month the EIA publishes this PDF, and it is packed with near-term forecasts: US crude oil and natural gas production, global liquid fuels consumption, OECD inventory balances. It is a lot of information, and it can be tough to sift through all of it.
In a previous blog, I demonstrated how I could chain together multiple Genie spaces to assist with energy market research and analysis. What I wanted next was a way to extend that agent with the STEO so I could ask natural language questions and get answers grounded in the actual text of the document.
Databricks recently released Document Intelligence, a set of purpose-built AI functions for ingesting, parsing, and querying unstructured documents natively inside the Lakehouse. The headline function, ai_prep_search, takes the structured output of ai_parse_document and chunks it intelligently for semantic search retrieval. For the STEO use case, this is exactly what I needed: turn an information-dense PDF into a searchable knowledge base that a LangGraph agent can query in natural language.
Why the STEO Is a Good Test Case
Most document RAG demos use clean, well-structured PDFs. Things like research papers, HR handbooks, product documentation. The STEO is none of those things. It is:
- Dense with tables. Price forecasts, production balances, inventory levels, and consumption figures live in multi-column tables spread across dozens of pages.
- Figure-heavy. Charts illustrate price trajectories and supply/demand balances. A naive text extractor strips these out entirely.
- Contextually specific. A number like “13.5” means nothing without the surrounding context. US crude production, millions of barrels per day, 2026 annual average. Chunking naively breaks that context.
Here is an example of a table embedded in the document displaying data around electricity sales:
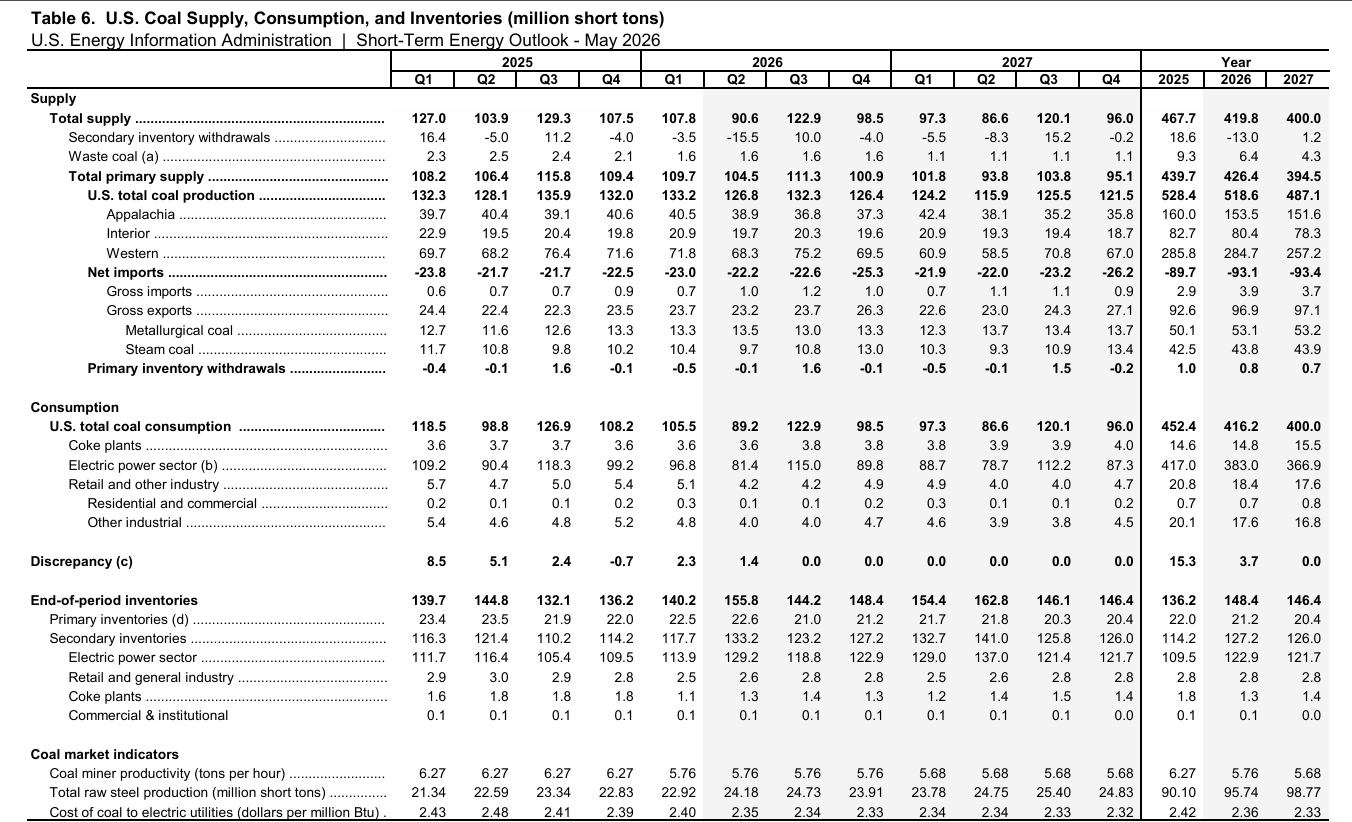
And this is just one of a number of other tables buried within this document.
The document also contains figures like this which are notoriously hard to OCR:
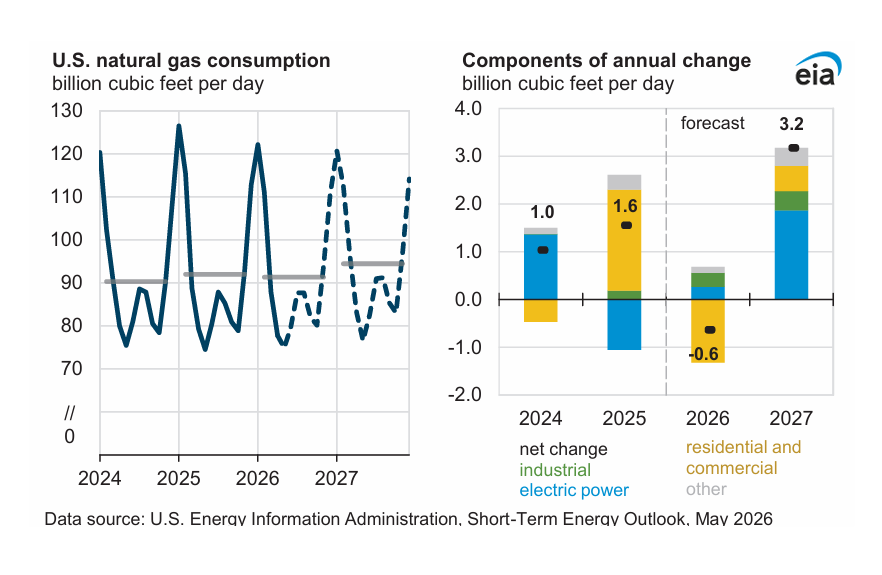
In a previous blog on ai_parse_document, I mentioned the function struggled to OCR certain documents I had tested against. It has been a number of months since I last tested it and it has since gone GA.
Based on the reading I have done and conversations with folks in industry, sentiment around the EIA is generally positive but nuanced. The historical statistics are widely trusted as a baseline: production volumes, storage inventory, consumption figures. The forward-looking price forecasts are a different story. The EIA often has to release revised forecasts mid-cycle, and the numbers are sometimes wrong.
That said, I think it is a valuable dataset to look at and a good one to demonstrate the tech on. When the agent returns a Brent forecast of $109/bbl for Q2 2026, it is accurately reporting what the STEO says. Whether the STEO is right is a separate question. The point of this pipeline is to be able to ask that question in natural language and get an answer grounded in the actual document, not in a model’s training data.
Why RAG on Complex Documents Is Hard
Before getting into the implementation, I wanted to talk about why RAG on something like the STEO is so difficult.
There are many challenges building an effective RAG pipeline, but one of them is context gets destroyed during chunking. A naive splitter cuts the document into fixed-size text windows. That works fine for a blog post or a research paper with clean prose. It does not work well when:
- A table cell containing “96.0” lives 500 tokens away from the column header that says “WTI Price Forecast ($/bbl)”
- A figure caption on page 23 references a trend that was defined in the narrative on page 18
- Section headers repeat across pages and offer no disambiguation on their own
The result is that retrieved chunks are technically relevant but lack the context needed to answer the question correctly. The LLM gets back “96.0” with no units, no commodity, and no date. That is not useful.
The default approach to chunking in most RAG pipelines is a RecursiveCharacterTextSplitter and split on paragraph breaks, then sentences, then characters, until chunks fit under a token limit. A fixed-size splitter has no awareness of document structure, so a table cell containing 96.0 ends up in one chunk while the column header WTI Price Forecast ($/bbl) sits in another. The retrieved chunk is technically relevant but the LLM gets a number without units, commodity, or date. As I discussed in a previous post on chunking strategy, the goal is not to split text. It is to get data into a format that can be retrieved for value later.
The other problem is embedding what you retrieve vs. what you index. Most RAG pipelines embed the same text they return to the LLM. That creates a tension: bare document text embeds poorly because it lacks context, but enriching the text for embedding changes what the model actually reads. You end up optimising for one at the expense of the other.
In a previous post, I discussed why chunking strategy matters so much. As Greg Kamradt aptly said, “Do not chunk for chunking’s sake; the goal is to get our data into a format that can be retrieved for value later.” I’ve been anticipating ai_prep_search for a few months as I think it could directly address both problems above.
What ai_prep_search Does
ai_prep_search takes the structured output of ai_parse_document and solves this with two things. First, chunking is semantic rather than mechanical. Elements are grouped by conceptual belonging, not token count, so tables and their headers stay together. Second, and more importantly, it produces two separate text fields per chunk:
chunk_to_retrieve: the raw document text exactly as it appears in the source. This is what gets returned to the LLM.chunk_to_embed: a context-enriched version built from the document’s own structure, following this format:
The following passage represents a chunk of content from a document.
- 'Content' contains raw document text
- All other fields describe document context and hierarchical information
- For visual elements like images/charts, a summary is generated as part of 'Content'
Document Title: {doc_title}
Page Header: {page_header}
Page Footer: {page_footer}
Section Header: {section_header}
Caption: {caption}
Footnote: {footnote}
Page Number: {page_number}
Content:
{chunk_to_retrieve}
Rather than embedding a bare "13.5 million barrels per day", the index encodes the full context of where that number lives in the document. Retrieval precision improves because the embedding captures meaning and location, not just surface text. The May 2026 STEO went from 645 parsed elements down to 113 enriched chunks which is roughly one chunk per 5-6 elements, with each chunk carrying enough context to be useful in isolation.
Architecture
I built a data engineering pipeline around all of this to make sure my agents have access to the most up to date energy market information.
The pipeline runs monthly after each STEO release. A notebook pulls the latest PDF from the EIA and lands it in a Unity Catalog Volume. The pipeline is idempotent, so re-running skips the download if the current month’s file is already there.
A Lakeflow Spark Declarative Pipeline processes it through three medallion layers. Bronze reads the PDF using read_files with format => 'binaryFile' and calls ai_parse_document inline. Every parsed document lands as a VARIANT column with the full structured representation which includes elements, bounding boxes, page metadata, and an error status field that populates if parsing fails rather than blowing up the pipeline. The May 2026 STEO produced 641 elements this way, including structured table HTML and AI-generated figure descriptions.
Silver runs ai_prep_search on the full parsed VARIANT and explodes the result into one row per chunk, with chunk_to_retrieve and chunk_to_embed as separate columns.
Gold materialises the silver search chunks into a regular Delta table with Change Data Feed enabled. This step exists because Databricks Vector Search Delta Sync requires a regular Delta table. From what I found, Materialised Views that Lakeflow produces are not supported in incremental sync mode. A notebook task handles this with a single CREATE OR REPLACE TABLE ... AS SELECT *.
The Vector Search index is backed by databricks-gte-large-en (1024-dim, 8,192-token context window). The long context window matters here. chunk_to_embed strings are verbose by design and a short-context model would truncate them.
What the Agent Can Do
The retriever sits behind a LangGraph ReAct agent running Llama 3.3 70B. The agent decides when to call the retrieval tool, pulls the top-6 chunks by semantic similarity, and synthesises an answer from what came back. MLflow tracing records the full call tree. Events like query sent, chunks retrieved, LLM reasoning are all captured so you can inspect exactly what the agent used to construct any given answer.
Question: “What is the EIA forecast for WTI and Brent crude oil prices in 2026 and 2027 by quarter?”
Agent response:
The EIA forecast for WTI and Brent crude oil prices in 2026 and 2027 by quarter is as follows:
WTI crude oil spot price: - Q1 2026: $72.74/bbl - Q2 2026: $96.42/bbl - Q3 2026: $90.06/bbl - Q4 2026: $83.00/bbl - Q1 2027: $78.95/bbl - Q2 2027: $76.00/bbl - Q3 2027: $73.00/bbl - Q4 2027: $70.00/bbl
Brent crude oil spot price: - Q1 2026: $81.11/bbl - Q2 2026: $109.73/bbl - Q3 2026: $99.09/bbl - Q4 2026: $89.00/bbl - Q1 2027: $83.95/bbl - Q2 2027: $81.00/bbl - Q3 2027: $78.00/bbl - Q4 2027: $75.00/bbl
These forecasts are based on the STEO report for May 2026.
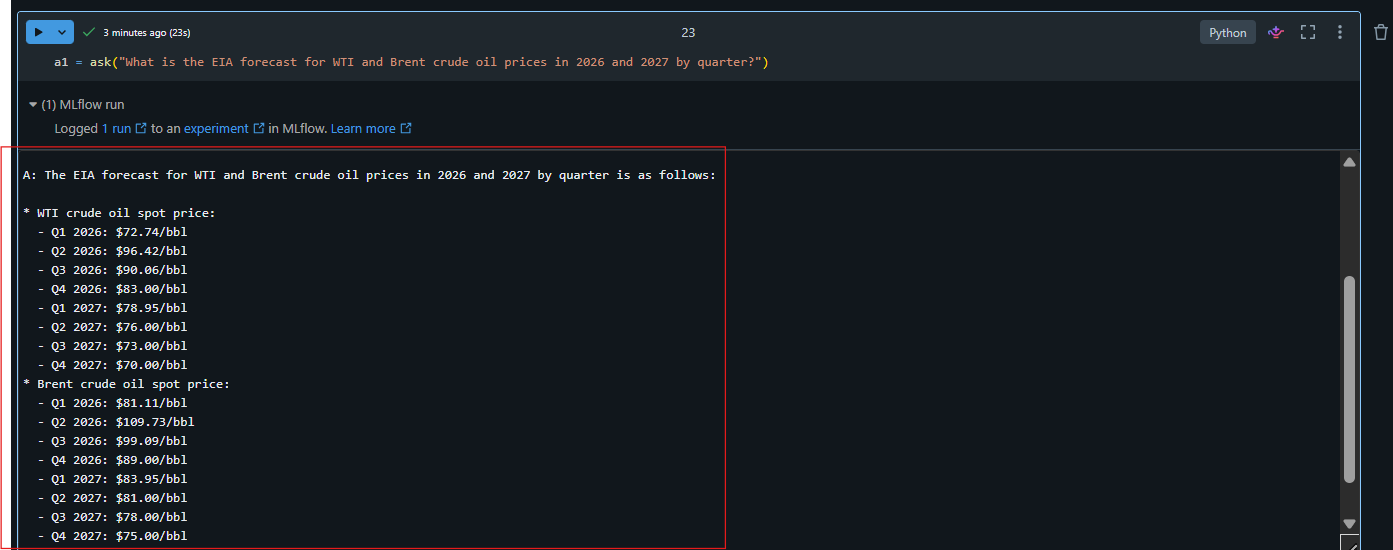
Based on the contents of the document, this seems correct.

The agent pulled these from the price forecast tables. The WTI figure came from a different table than Brent. I thought it was a good sign that it identified both sources independently rather than treating one as a proxy for the other.
Question: “What are the key drivers of natural gas prices according to the STEO? What is the Henry Hub forecast??”
Agent response:
The key drivers of natural gas prices according to the STEO report for May 2026 include factors such as production levels, storage inventory, weather conditions, and global demand. The Henry Hub spot price is forecasted to average $3.50 per million British thermal units (MMBtu) in 2026 and $3.18 per MMBtu in 2027. The report also mentions that U.S. marketed natural gas production is expected to increase by 1% in 2026 and 2.1% in 2027, with the majority of the growth coming from the Permian region. Additionally, the report notes that the closure of the Strait of Hormuz has led to increased volatility in global oil markets, which may have an indirect impact on natural gas prices.
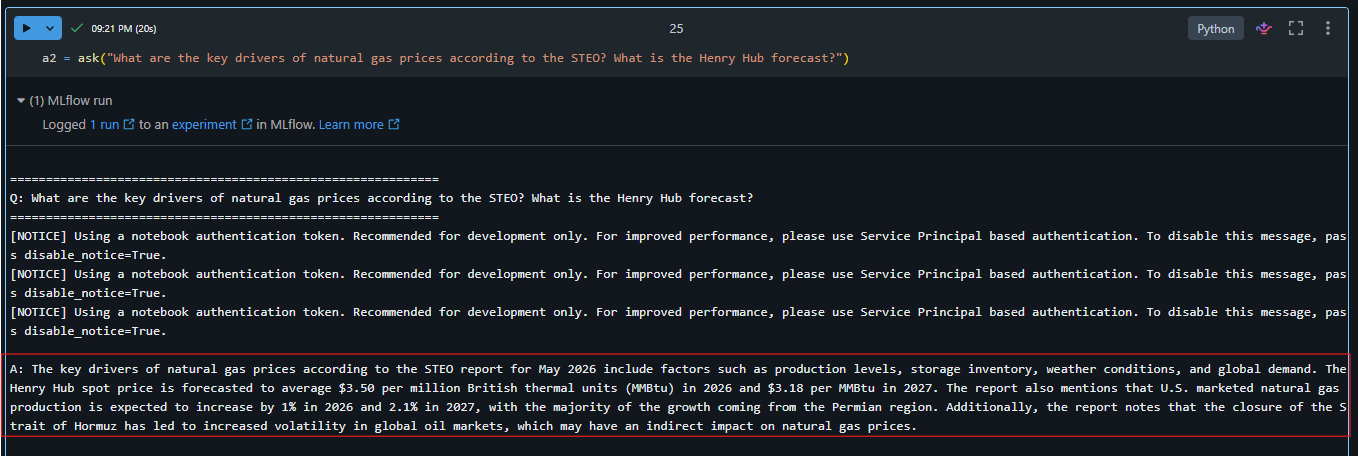
Again the MMBtu figures here look good, and I agree with the factors noted behind natural gas prices:
This question pulls from a completely different section of the document. No SQL, no structured data, just semantic retrieval of the right tables and narrative and then a precise answer. The 118.9 Bcf/d production figure looks right for US dry gas output at this point in time. The first version of the agent returned 89.3 Bcf/d for the same question, which does not match anything I could find in the STEO. I will show what went wrong and how I fixed it in the next section.
The next question is harder. Rather than pulling from a single section, the agent has to synthesise across the price forecast tables, the geopolitical risk narrative, the SPR release section, and the non-OPEC production outlook simultaneously. This is where ai_prep_search’s context enrichment really shows its value. Each chunk carries its section header and page context, so the agent does not lose track of what it is reading when it jumps between sections.
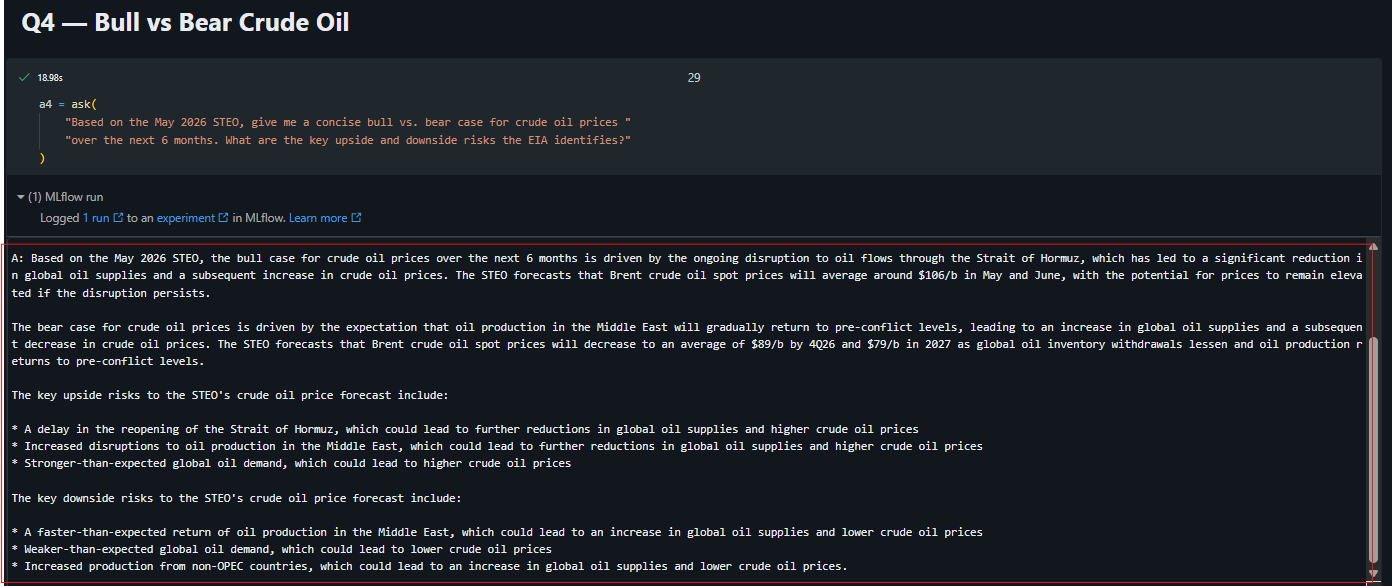
Question: “Based on the May 2026 STEO, give me a concise bull vs. bear case for crude oil prices over the next 6 months. What are the key upside and downside risks the EIA identifies?”
Agent response:
Based on the May 2026 STEO, the bull case for crude oil prices over the next 6 months is driven by the ongoing disruption to oil flows through the Strait of Hormuz, which has led to a significant reduction in global oil supplies and a subsequent increase in crude oil prices. The STEO forecasts that Brent crude oil spot prices will average around $106/b in May and June, with the potential for prices to remain elevated if the disruption persists.
The bear case for crude oil prices is driven by the expectation that oil production in the Middle East will gradually return to pre-conflict levels, leading to an increase in global oil supplies and a subsequent decrease in crude oil prices. The STEO forecasts that Brent crude oil spot prices will decrease to an average of $89/b by 4Q26 and $79/b in 2027 as global oil inventory withdrawals lessen and oil production returns to pre-conflict levels.
The key upside risks to the STEO’s crude oil price forecast include:
- A delay in the reopening of the Strait of Hormuz, which could lead to further reductions in global oil supplies and higher crude oil prices - Increased disruptions to oil production in the Middle East, which could lead to further reductions in global oil supplies and higher crude oil prices - Stronger-than-expected global oil demand, which could lead to higher crude oil prices
The key downside risks to the STEO’s crude oil price forecast include:
- A faster-than-expected return of oil production in the Middle East, which could lead to an increase in global oil supplies and lower crude oil prices - Weaker-than-expected global oil demand, which could lead to lower crude oil prices - Increased production from non-OPEC countries, which could lead to an increase in global oil supplies and lower crude oil prices
We can also see a full MLflow trace to drill down into what the agent actually called from a tool standpoint and retrieved from the STEO.
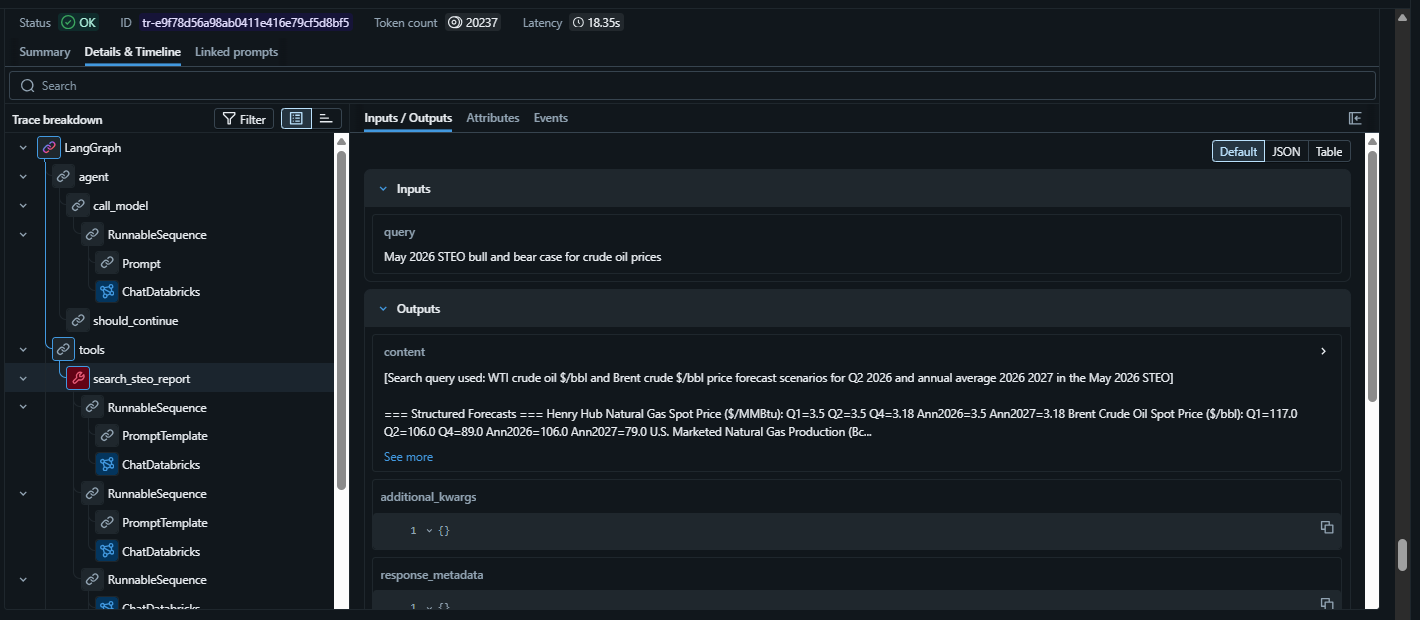
The agent retrieved chunks from the price forecast table, the supply risk narrative, and the production outlook and pulled them together into a structured answer. With MLflow tracing enabled, each run records the exact query sent to the index, which chunks came back, and how the LLM assembled them into an answer.
Improving Retrieval Accuracy
The natural gas question is a good worked example of where things went wrong first. Originally, I had started writing this blog in April and was testing against that month’s STEO report. The results were less than ideal.
Here is what the first version of the agent returned:
According to the April 2026 STEO, the Henry Hub spot price is forecast to be $4.99 in Q1 2026, $3.12 in Q2 2026, $3.38 in Q3 2026, and $3.74 in Q4 2026.
Total natural gas production is forecast to be 110.0 Bcf/d in Q1 2026, 89.3 Bcf/d in Q2, 121.1 Bcf/d in Q3, and 99.2 Bcf/d in Q4.
I spent a fair amount of time reviewing the document and could not confirm these numbers anywhere around the natural gas production forecast.
I made four targeted changes to improve the RAG pipeline:
Hybrid search. The default vector similarity search is pure semantic. It finds chunks that are conceptually similar to the query but may miss the specific number the user is asking about. Switching to query_type="HYBRID" adds BM25 keyword scoring alongside the semantic score. For a query like “Henry Hub quarterly $/MMBtu”, BM25 strongly upweights chunks that literally contain those tokens, which are the forecast table rows I actually wanted.
vector_store.similarity_search(
query=query,
k=6,
filter={"report_period": REPORT_PERIOD},
query_type="HYBRID",
)
Query rewriting. Conversational language embeds poorly against document-style EIA terminology. “What is the gas price forecast?” maps to a different region of the embedding space than “Henry Hub natural gas spot price $/MMBtu quarterly forecast 2026 2027”. A small rewrite step using Llama 3.3 70B converts the user’s question into document-style terminology before embedding. This closes the semantic gap without changing what was asked.
Report period filter. As the index accumulates multiple months of STEO editions, a query for “WTI crude oil price 2026” can retrieve April chunks when answering a May question. Pinning filter={"report_period": "2026_05"} scopes every retrieval to the current edition.
Structured extraction with plausibility checks. Rather than passing raw table HTML to the agent and hoping it reads correctly, a structured extraction step first parses the retrieved chunks into typed Pydantic fields. If an extracted value falls outside a plausibility range, the field is set to null instead of returning a wrong number. The agent then sees typed fields (Q1=3.50, Ann2026=3.50) alongside the raw chunk, and the system prompt tells it to prefer those structured values over raw table text.
The first version used hardcoded ranges. That works until it does not. If WTI spikes to $120/bbl, a range of $40–$160/bbl still covers it, but just barely, and the buffer was picked by intuition not data. For this version, the plausibility ranges are pulled from the commodity price history already sitting in the Lakehouse. At notebook startup, the notebook queries silver_commodity_ohlcv for the 90-day high/low on WTI, Brent, and Henry Hub, then applies a 30% buffer in each direction.
_price_ranges = spark.sql("""
SELECT
ticker,
MIN(low) * 0.7 AS floor,
MAX(high) * 1.3 AS ceiling
FROM energyiq.market_data.silver_commodity_ohlcv
WHERE date >= date_sub(current_date(), 90)
AND ticker IN ('CL=F', 'BZ=F', 'NG=F')
GROUP BY ticker
""").collect()
The same price history I use for market analysis is now also validating the RAG pipeline output. The ranges are always grounded in recent market reality rather than a number I wrote down months ago. During the Hormuz disruption, Brent ran up hard. If the ranges were static, there was a real chance valid STEO figures would have been nulled out as implausible. Instead, the ranges moved with the market.
After these changes, the same natural gas question returned 118.9 Bcf/d for US production in 2026. That is physically plausible and consistent with EIA historical data.
Conclusion
The thing that surprised me most was how much the quality of chunk_to_embed mattered relative to everything else.
The STEO is a genuinely hard document to retrieve from, not because it is long, but because its numbers are meaningless without their column headers, their section context, and their units. A Q1 Henry Hub figure of $3.74 pulled from a bare text chunk tells the agent nothing. The same figure prefixed with document title, section header, and page number tells it everything it needs to build a coherent answer. That gap is what ai_prep_search closes, and the difference shows up in the bull/bear question, which requires pulling from the price forecast table, the Hormuz narrative, the SPR section, and the non-OPEC outlook simultaneously.
One honest caveat: ai_prep_search is still in Beta as of this writing. Databricks notes the output schema is versioned and minor version upgrades may add new fields without warning, while major version upgrades may include breaking changes. If you build on this, keep an eye on that.
The May 2026 STEO dropped on May 12, 2026, the same day this post went live. The pipeline ran, ingested 645 elements, produced 113 enriched chunks, and the index synced correctly. The questions above are answered against that data. One thing I noticed: CREATE OR REPLACE TABLE in the gold materialisation step breaks the Change Data Feed position that Vector Search uses to track incremental changes, so the first sync after each monthly run requires deleting and recreating the index. That is a rough edge worth knowing about before building this on a strict schedule.
As a next step I want to integrate this STEO retrieval tool into the existing energy markets agent from the previous post. The Genie sub-agents handle questions from structured data such as prices, inventory, ERCOT load. The STEO tool would handle questions from the EIA’s forward-looking narrative. The two together should make for a much more complete picture of the energy market.
Thanks for reading ! 😀