
Strategies for Managing LLM Memory 🤖🧠

Although chatbots are not the only use case/way to interact with LLMs it has certainly become one of the more popular.
Building production chatbots requires more than just a wrapper on top of an LLMs API. Due to the popularity of ChatGPT, users have come to expect a robust chat experience that considers conversation history and the users intent. In this blog I wanted to step through a few strategies I have employed in the past for managing chat history along with some advantages and considerations.
LLMs, by default, do not have memory. Each API call is stateless, meaning the model does not retain any knowledge of past interactions. This poses a challenge when building chat applications, as users expect the AI to remember previous messages, maintain context, and provide coherent responses across turns.
To bridge this gap, developers must implement their own memory management strategies. These strategies vary in complexity from simple in-memory storage to persistent databases each with its own trade-offs in terms of scalability, performance, and cost.
There is no one size fits all strategy and the intent of this blog is to step you through various approaches and you can decide which will work best for your use case.
This will be a conceptual guide but if you would like me to build out one of these strategies in a dedicated blog, please let me know!
Considerations 🤔
When designing a chatbot with memory, several factors influence how effectively it can retain and retrieve past interactions. These include how much context to store, where to store conversations, and how to efficiently fetch relevant history. Below are key considerations for implementing LLM memory.
Managing Context with LLMs 🤖🗨️
LLMs process interactions based on the provided context within their fixed token limit. Most models support context windows from 128K tokens (~96,000 words) to 1 million tokens (~750,000 words). For example, GPT-4o supports 128K tokens, while Gemini 1.5 Pro offers 1 million tokens.
A larger context window allows for extended conversation memory, improving coherence, but comes with trade-offs:
-
Pros: Maintains full conversation history (within limits), avoids external storage complexity.
-
Cons: Higher token costs, increased latency, and constraints based on model limits.
To optimize memory usage, developers should curate which messages are included in the prompt, summarize past exchanges, and truncate older, less relevant content.
Storing and Retrieving Chat History 🗣️
For persistent memory beyond an LLMs context window, external storage is necessary. The right database choice depends on the application’s complexity and retrieval needs:
Structured Storage (Document & Vector Databases):
-
Document databases store structured chat logs and enable retrieving recent messages efficiently. A common approach is fetching the last N messages to maintain context.
-
Vector databases store past interactions as embeddings, allowing retrieval of semantically similar messages rather than just the most recent ones. This is useful for assistants that need long-term memory without bloating the LLM prompt. (Learn more about vector search here)
Other key factors to consider 🤔🤖
-
Scalability – How well the solution handles increasing users and message history.
-
Retrieval Speed – Ensuring stored messages can be accessed efficiently without slowing responses.
-
Privacy & Security – Storing chat data securely, especially in regulated industries
Let’s jump into a few practical strategies I have leveraged for memory management with LLMs.
Strategy 1️⃣: Leveraging Arrays
Let’s start with the simplest way to manage chat history, which might be a good fit for testing or single-user scenarios.
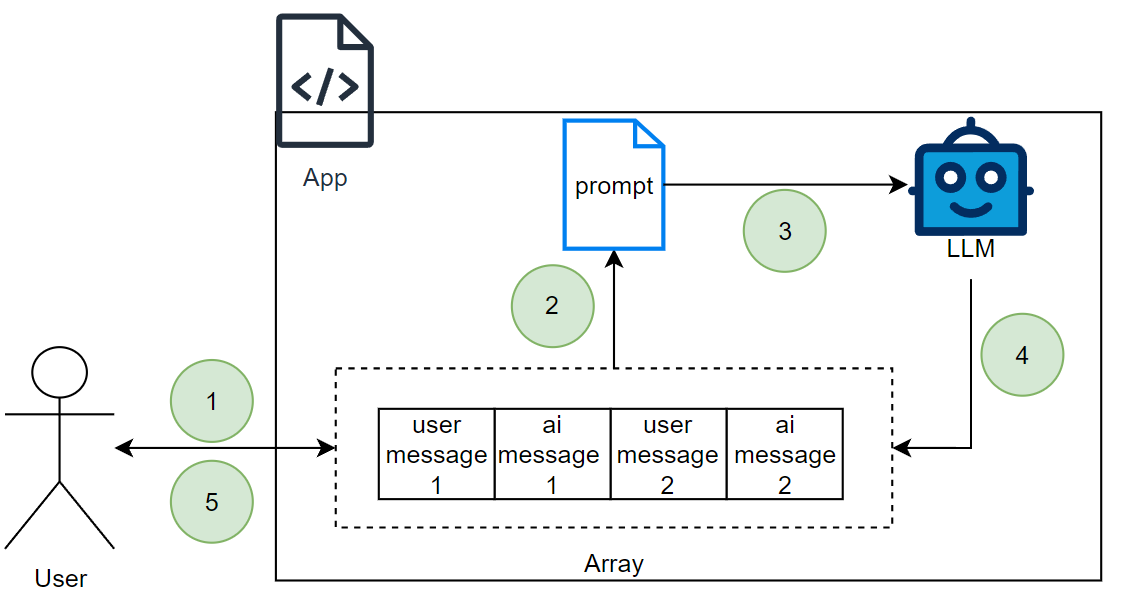
This first strategy involves using an in-memory data structure (an array) to manage the chat history. I would say this is a very naïve and simple approach but allows you to mock basic chat history functionality very quickly. It is naïve because this does not scale for multiple users and is difficult to persist the data accross sessions. Below is a diagram that shows off the approach at a high-level:
-
User will send input to our application. This input will be appended to an array.
-
The latest input will be passed to a carefully crafted prompt along with the chat history.
-
The prompt is sent to an LLM.
-
The LLM responds and the AI message is appended to the array.
-
A response is provided to the user.
I have leveraged this strategy to quickly mock LLM memory locally, but this does scale very well. Here are a few things to consider when leveraging this approach.
Advantages:
-
Quick to implement
-
Sufficient for prototyping or single-user applications
Considerations:
-
Does not scale well for multiple users
-
Chat history is lost when the application restarts
-
Cannot persist conversations across sessions
Strategy 2️⃣: Leveraging Document Databases
As your chatbot moves beyond simple prototypes and starts serving multiple users, storing chat history in a document database becomes a logical next step. This strategy allows you to persist chat data and support multiple users without losing track of conversations. Document databases, such as MongoDB, DynamoDB, or Couchbase, are particularly well-suited for this task due to their flexible, schema-less nature.
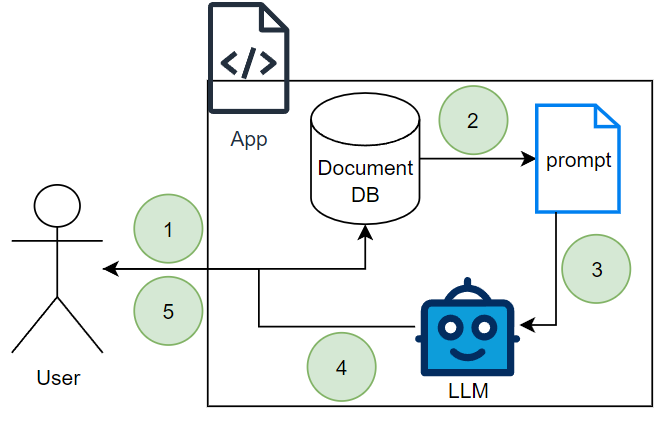
Here’s an overview of how this strategy works:
-
The user sends input to the chatbot application.
-
The application fetches the relevant chat history from the document database using a unique identifier (e.g., a user_id or session_id).
-
The retrieved chat history is combined with the latest user input to craft a prompt and send it to the LLM.
-
Once the LLM responds, both the user input and the AI response are appended to the chat history, and the updated conversation is stored back in the document database.
-
A response is provided back to the user.
Here’s a simple example of how you might structure chat history in a document database like MongoDB:
{
"session_id": "12345",
"user_id": "67890",
"messages": [
{
"role": "user",
"timestamp": "2025-01-01T12:00:00Z",
"content": "Hello, can you help me with my order?"
},
{
"role": "ai",
"timestamp": "2025-01-01T12:00:05Z",
"content": "Of course! Could you provide me with your order number?"
}
],
"last_updated": "2025-01-01T12:00:05Z"
}
This approach scales much better and is a strategy I have used in a few production scenarios. Here are some key takeaways,
Advantages:
-
Supports multiple users and sessions.
-
Data is persistent, enabling conversations to resume at any time.
-
Flexible schema for storing complex or evolving message data.
Considerations:
-
Increased latency compared to in-memory solutions.
-
Requires additional infrastructure and may incur higher costs.
This strategy strikes a good balance between simplicity and scalability, making it ideal for most production chatbot applications. However, as the volume of chat history grows or you require more advanced features (e.g., searchability or analytics), you might need to explore additional strategies like vector databases.
Strategy 3️⃣: Leveraging Vector Databases
Unlike strategy 2, which retrieves a fixed number of previous messages (e.g., the last 10 interactions), vector databases enable a more semantic approach to memory. Instead of relying on strict chronological order, this method retrieves the most relevant past messages based on their meaning.
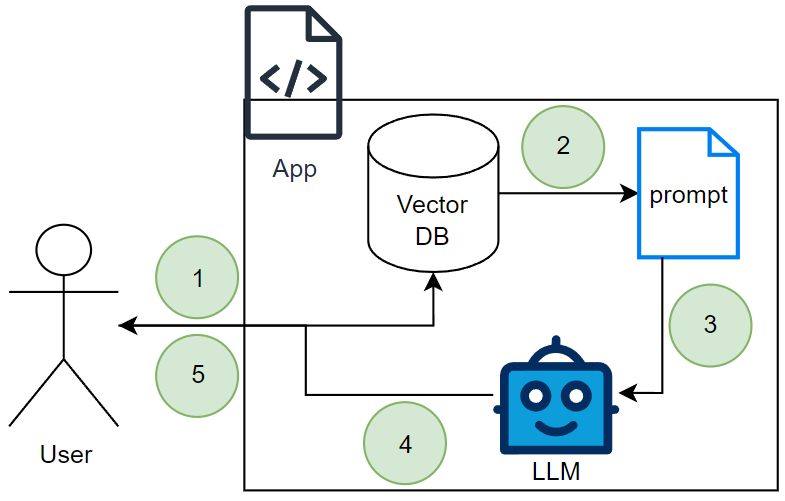
This effectively looks the same as strategy 2, but this time we are swapping a document database for a vector database and instead of retrieving recent messages, we retrieve semantically similar ones.
-
The user sends a message to the application.
-
The app queries the vector database, searching for past interactions that are semantically similar to the current message. This ensures the model retrieves contextually relevant information instead of just the last few messages. This information is injected into a prompt.
-
The formatted prompt is sent to the LLM.
-
The LLM processes the prompt as well as the user input and generates a response.
-
The app sends the response back to the user, completing the interaction. The latest conversation is embedded and stored in the vector database for future reference.
Here are some takeaways from this strategy,
Advantages:
-
Works well even with a large number of past interactions.
-
Instead of just retrieving the last few messages, the system retrieves information that is most contextually similar to the current query.
-
Even if a conversation spans multiple sessions, relevant details can still be recalled.
Considerations:
-
Requires efficient retrieval mechanisms to avoid high latency.
-
Embedding quality and vector search parameters impact the accuracy of retrieved results.
-
May need metadata filtering to ensure the retrieval is scoped to the right topic, user, or session.
This approach significantly improves chatbot memory by making past interactions searchable based on meaning, rather than just time-based proximity.
Conclusion 🏁
Choosing the right strategy for managing chat history depends on your specific use case and long-term goals. Each approach whether it’s using an in-memory array, a document database, or a vector database offers unique advantages and trade-offs. Simple solutions work well for lightweight applications or prototypes, while more advanced architectures enable features like personalization, semantic search, and scalability.
As your user volume grows, evolving towards more sophisticated techniques such as vector databases can enhance efficiency and retrieval without unnecessary complexity upfront. Balancing performance, cost, and maintainability is key to selecting the right approach.
I hope this blog has provided a clear overview of different strategies and how they can be applied. With a solid understanding of these options, you can make informed decisions to optimize your chatbot’s performance and user experience.
Thanks for reading!