
📖 OCR Made Simple with Databricks AI Functions

About a year ago, I wrote a blog on how to leverage Databricks AI Functions for some exciting use cases. Within the last few months, ai_parse_document has been released and it allows you to perform OCR on your documents in Unity Catalog.
Prior to this feature coming out in Databricks, we leveraged Azure AI Document Intelligence quite heavily to OCR checks and contracts.
Document Intelligence worked great, and I have no complaints about the service. The biggest challenge was the development/technical overhead associated with integrating with that service. Following along with the principles laid out in The Art of Keeping Things Simple, we were trying to find ways to reduce our tool sprawl and the burden on the engineers to maintain another integration.
For this reason, AI Parse was very intriguing. I wanted to spend some time in this blog going through some initial findings.
🤷♂️ What is ai_parse_document()
First, let’s understand what ai_parse_document() is exactly. According to the Databricks official docs:
The
ai_parse_document()function invokes a state-of-the-art generative AI model from Databricks Foundation Model APIs to extract structured content from unstructured documents.
It basically OCRs our unstructured data.
But what does this mean exactly?
OCR (Optical Character Recognition) is the process of converting text from images, scanned documents, or PDFs into machine-readable data. In this case, ai_parse_document() takes unstructured data and converts it to markdown. Modern AI models can go beyond simple character recognition and:
- 📑 Preserve structure (tables, forms, and hierarchies instead of flat text) by converting the text to markdown format.
- 🤝 Integrate directly with downstream analytics (e.g., automatically loading contracts, invoices, or receipts into Databricks for analysis).
- 🔍 Improve search and compliance by making previously unsearchable PDFs part of your data lake.
And the best part in my opinion, this can all be invoked from a simple PySpark script.
🎬 ai_parse_document() in Action
NOTE: Make sure you have the requirements detailed prior to trying to run
ai_parse_document()! Specifically, the compute requirements and having Databricks Runtime 16.4 LTS or above installed. I made the mistake of not reading the doc before trying to use it and struggled trying to figure this one out 🤣.
Let’s take the sample check below as an example and upload it to a Unity Catalog volume.

Invoking ai_parse_document() is as easy as:
SELECT
path,
ai_parse_document(content)
FROM READ_FILES('/Volumes/test_dev/default/ai_parse_demo/sample_check.png', format => 'binaryFile');
The query takes a few seconds to run and outputs the following info:
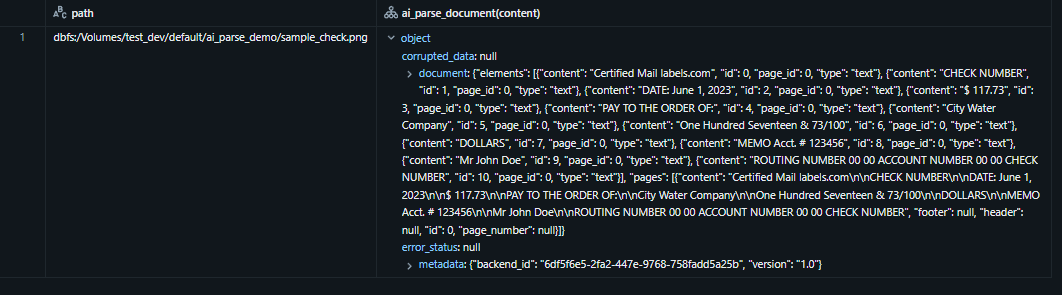
You will notice in that screenshot that the column ai_parse_document(content) presents a JSON structure with the output from the check.
It was even able to pick up the handwritten signature ‘Mr John Doe’, pretty impressive!
Data Weaver 🤝 AI Parse
Like Mark and I talked about in The Art of Keeping Things Simple, building object-oriented software is critical to scaling and evolving.
ai_parse_document() is a great example of that. We wanted to test it out, but we wanted to integrate it into our Data Weaver product to pressure test its functionality on large data sets in our lake.
Extending our internally built software, nicknamed Data Weaver, to include ai_parse_document() was pretty straightforward. Leveraging the ‘Structure Unstructured PDFs’ example, you can see that the DocumentIntelligenceTransform was being used to OCR contracts.
We can create a new transform and instantiate it the same way we did for the DocumentIntelligenceTransform. Example:
{
"stage": "dev",
"Read": {
"VolumeReader": {
"catalog_name": "catalog",
"schema_name": "schema",
"volume_name": "volume",
"files_to_process": files,
"full_load": false
}
},
"Transform": {
"AIParseTransform": {
"schema_name": "schema",
"temp_table_name": "ai_parse_temp",
"batch_size": 10,
"source_path": "/Volumes/catalog/schema/volume/"
}
},
"Write": {
"DeltaType1Writer": {
"connection": "data_lake",
"primary_keys": ["__SourceFile"],
"write_type": "insert_update",
"catalog_name": "catalog",
"schema_name": "schema",
"table_name": "ocr_refactor"
}
}
}
This allows engineers to quickly tie their unstructured data into this process.
Minus some concurrency/multithreading challenges, we have processed thousands of files through our new AIParseTransform transform and are getting solid results.
🥳 Conclusion
We had a few cases where the document could not be OCR’d. When running it through ai_parse_document(), a null response was returned. We are working with the Databricks product group to identify what the cause could be for this. It could be because the contract was handwritten in 1982 🤣.
However, we did test those same files (i.e., files pre-dating the year 2000) against Azure Document Intelligence, and we were able to successfully OCR them.
In one of our test scenarios, we processed 40 contracts using ai_parse_document(). Of these, 8 contracts (20%) could not be OCR’d. Notably, 7 out of these 8 failures (87.5%) were poorly scanned documents from before the year 2000, highlighting the challenge of extracting data from older, low-quality scans. This gives us an overall OCR success rate of 80%, with only a single contract (2.5%) failing for other reasons. I imagine other OCR tools would have a similar problem with these older contracts.
We also ran into concurrency and multithreading problems where we ran into errors like:
[REMOTE_FUNCTION_HTTP_RETRY_TIMEOUT] The remote request failed after retrying 10 times; the last failed HTTP error code was 429
At the time of writing this blog, this feature is in beta, so issues are to be expected.
Overall, I see huge promise in ai_parse_document() and the Databricks AI Functions as a whole. I am excited to see how they evolve and what new ones get added as time goes on.
Thanks for reading! 😀