
Monitoring GenAI Apps with LangSmith 👀🦜

The hype cycle around GenAI is still going strong and companies are trying to figure out how to best leverage the tech to help with their businesses. Amongst the hype, I think it is easy forget the age old practices and principles decades of software development has taught us. It is easy to neglect fundamentals such as the DevOps principals that can help take these GenAI applications into a production ready state.
There are many important components to the DevOps lifecycle:
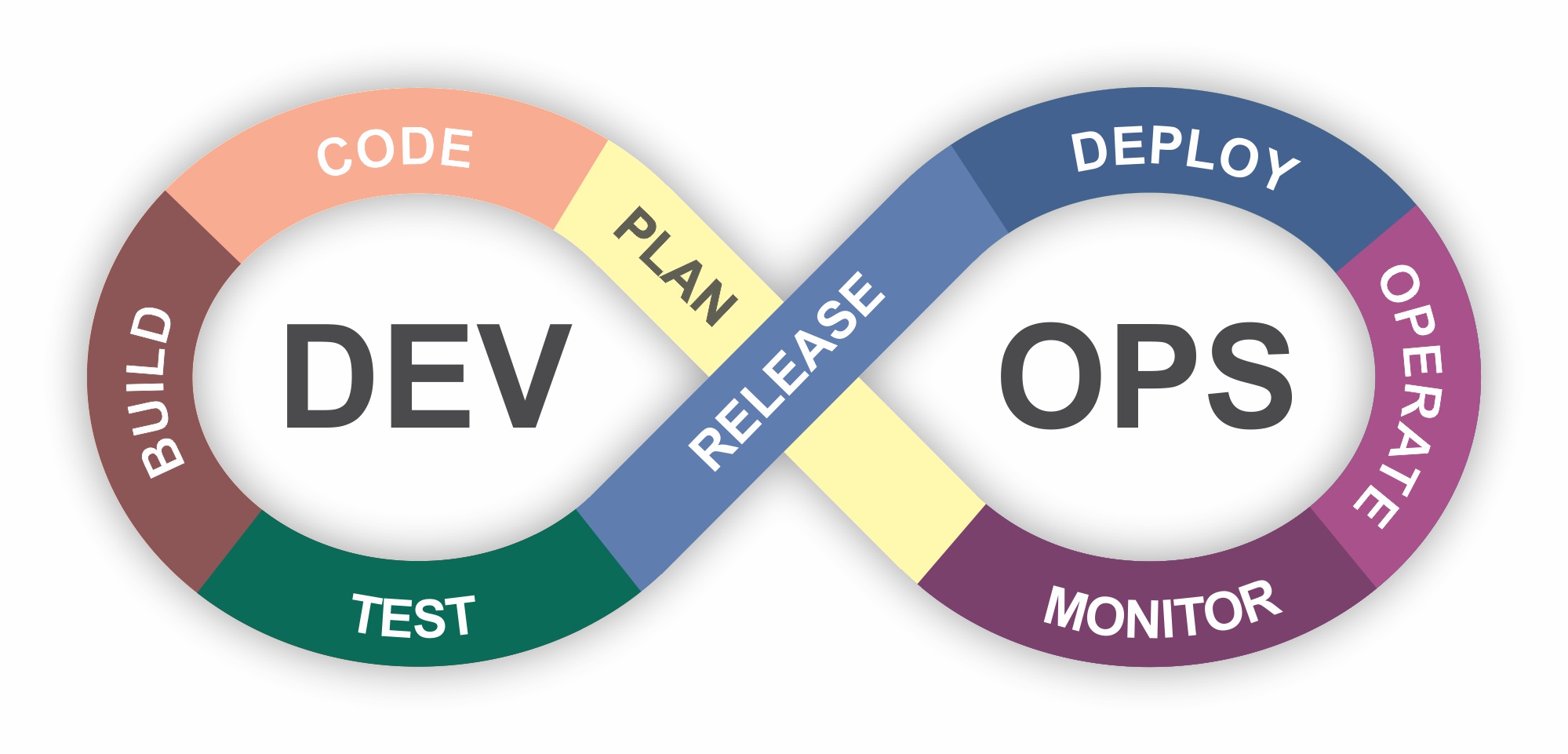
In this blog post, the primary focus lies on the critical aspects of ‘monitoring’, ‘coding’, and ‘testing’ within the DevOps lifecycle concerning the development of applications integrating Generative AI functionalities. It aims to address challenging questions from users such as, “When the ‘bot’ delivers an unexpected response, how can we precisely trace the sequence of actions executed by the agents?” Such inquiries underscore the indispensable role of a robust monitoring solution in effectively managing and troubleshooting complex AI-driven systems.
As I’ve been rolling out these apps into the wild, I’ve been bombarded with questions like the ones I mentioned earlier. So, I started tinkering with LangChain’s tool for testing and monitoring GenAI apps, known as LangSmith. With LangSmith now being offered in the Azure Marketplace, the barrier to entry to leverage tools like these in an enterprise setting is becoming lower and lower.
What is LangSmith? 🤷♂️
According to the LangSmith documentation, ‘LangSmith is a platform for LLM application development, monitoring, and testing’. I have personally used LangSmith with a couple projects and I found it incredibly useful for debugging things like ‘infite loops’ when you are working with things like multi turn agents, logging interactions with the bot, using it for fine-tuning, and capturing user feedback. LangSmith helps to answer questions like:
- How do I ensure outputs remain deterministic as my prompts evolve over time?
- How does mixing and matching different models affect my outputs?
- What happened when a particular prompt was passed through?
- What was the cost (ie: tokens) for a particular run?
- Are user’s satisfied with the LLM’s output?
LangSmith reminds me a lot of Azure Application Insights where just by adding an instrumentation key to your app, lots of insightful telemetry is enabled for you by default. It is very easy to get started but takes time to master!
Let’s jump in and get LangSmith set up to understand how it works!
LangSmith Setup ⚙️
LangSmith is very easy to setup and is exposed as a PyPI Package for easy installation.
First, let’s create and activate a python virtual environment and install dependencies. Note, the requirements.txt for this code can be found here for your reference.
python -m venv venv
venv\scripts\activate
pip install -r requirements.txt
Now that our environment is set up, let’s create a program that will interact with OpenAI’s GPT-3.5 model, send a prompt, and log the interaction in LangSmith. Below is a sample of my environment file, and I want to draw your attention to a few settings:
- LANGCHAIN_ENDPOINT: This is the LangSmith API Endpoint
- LANGCHAIN_API_KEY: LangSmith API Key Generated on your account
- LANGCHAIN_PROJECT: LangSmith project to send the traces
The above setting will enable tracing of your application in LangSmith.
To generate an API key, navigate to the LangSmith portal, navigate to settings, and select API Keys:
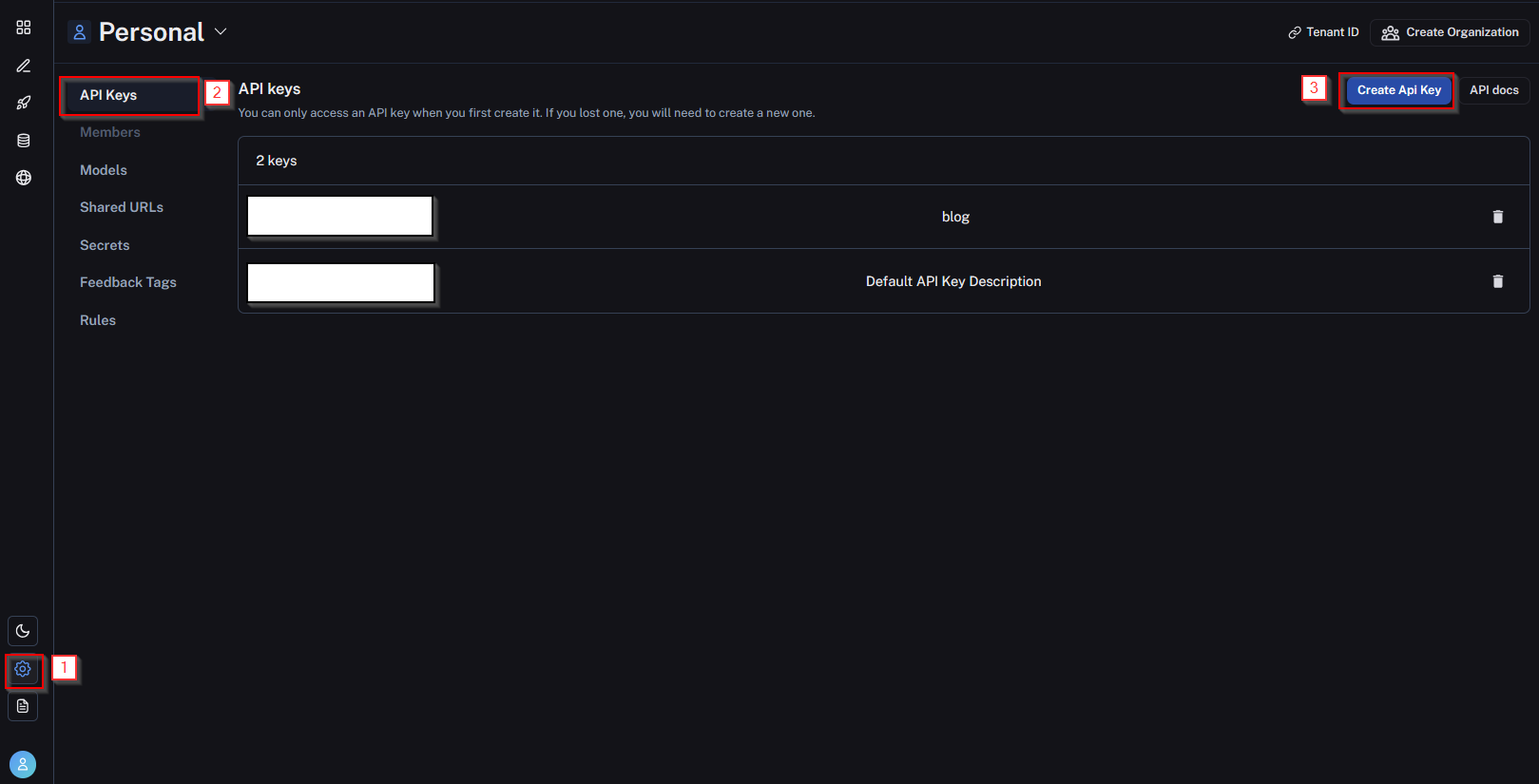
Generate an API key and place it in your environment file using the LANGCHAIN_API_KEY key. Once the API key is added to your environment file, let’s run the below code:
from langchain_openai import AzureChatOpenAI
import os
from dotenv import load_dotenv
load_dotenv()
llm = AzureChatOpenAI(api_key=os.getenv("AZURE_OPENAI_API_KEY"), azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"), deployment_name="gpt35_turbo", api_version="2024-03-01-preview")
print(llm.invoke("Hello, world!"))
Let’s jump in to LangSmith and have a look at the trace that appeared after running our code.
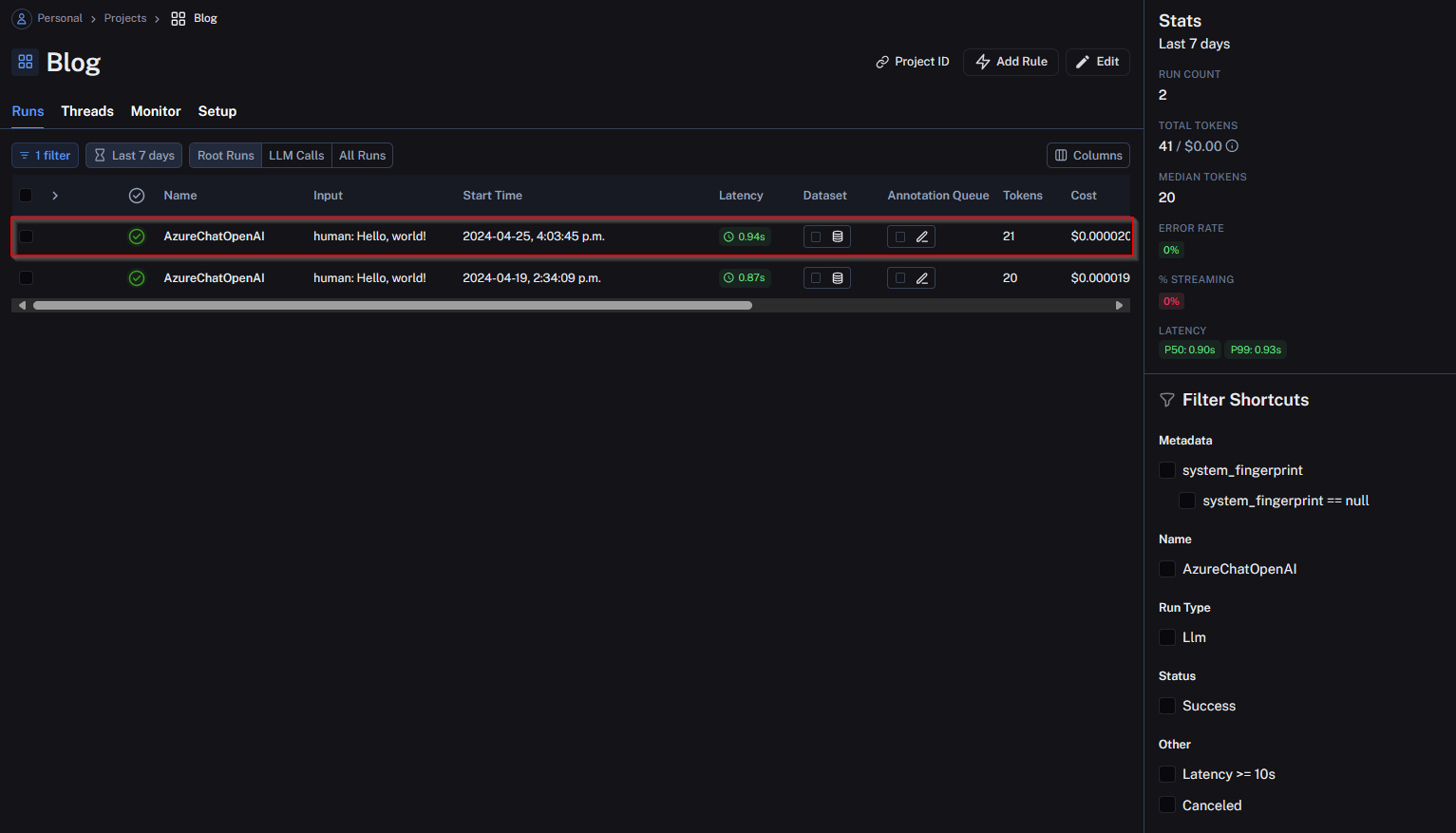
As you can see, it is incredibly easy to ‘instrument’ your application and send the logs to LangSmith. In the subsequent sections, I would like to dive a bit deeper into the various offerings in LangSmith like debugging, capturing user feedback, and fine-tuning! By no means will this be exhaustive, but I would like to provide an overview.
LangSmith in Practice ⚽
I have created a sample application to demonstrate the capibilites of LangSmith and have open sourced it here. At a high-level, the application does the following:
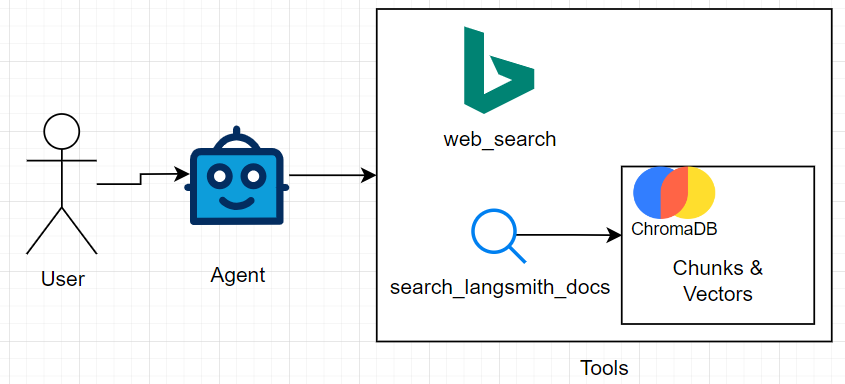
The user will send in some input to an agent that will then route to the tool the agent thinks will resolve the user’s input. In this case, I have provided the agent with two tools:
- web_search - Has access to the bing search API
- search_langsmith_docs - Will have access to a select few chunked and vectorized pages from the LangSmith documentation
For the search_langsmith_docs tool, I had to first chunk and vectorize a few web pages from their documentation. I have open sourced the code I leveraged to do just that. You can find that here. You will notice, I have leveraged a few of LangChains abstractions to load the web pages into ChromaDB.
After running the above code, I can see the documents in ChromaDB and we are good to start using the search_langsmith_docs tool:

The web_search tool works out of the box and only requires a Bing search API key so no additonal setup is required. I have created a resource in Azure for it.
Anatomy of a Trace 🫀
Let’s run our application and pass through a few different queries:
- using the langsmith docs, can you tell me what tags are?
- using bing, can you tell me what langsmith tags are?
- can you tell me what tags are?
A trace in LangSmith provides many interesting data points. Looking at the first query, we can see a few important metrics right away which I have annotated below:
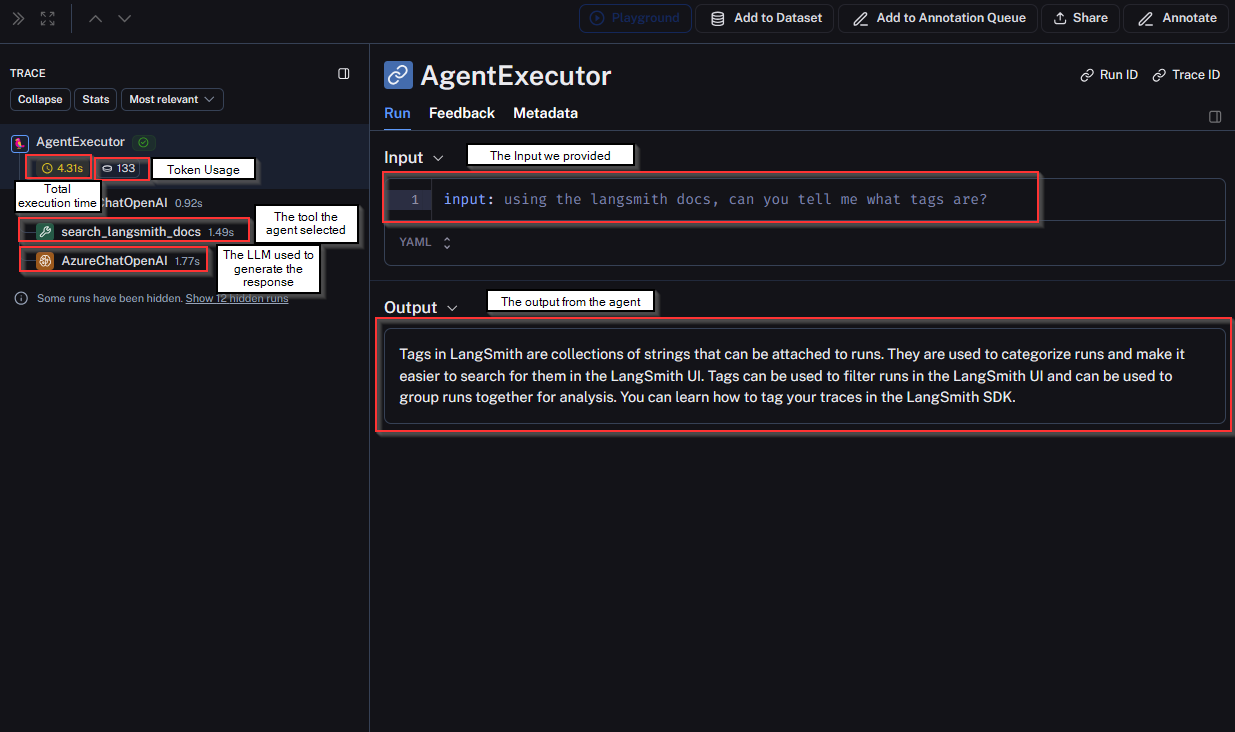
Note, all of these metrics are out of the box, and come as soon as you add the LangSmith API key to your app.
Let’s walk through a few scenarios where these traces prove helpful.
Troubleshooting LLM Output 🤔
I’ve come across inquiries from end users who are using live applications, which resemble the following: “The bot provided an unexpected answer. What might have caused this?” To effectively answer this question, we need to dig into the logs, or in this case, the LangSmith traces to understand what the agent decided to do based on user input. Let’s say the users input was ‘can you tell me what tags are?’ and they did not receive the answer they would expect.
Going through my troubleshooting steps, the first thing I would likely do is see if the underlying data the agent has access to, even contains information about a tag in LangSmith. If the agent has not been grounded in the relevant data, we know the response back will not contain the information the user is looking for. In this case, we know the agent does via the search_langsmith_docs tool we created earlier, so what else could be the problem?
Having a look at the trace I can see a few things:
- There is no reference to information from the LangSmith documentation. Ie: ‘Tags are collections of strings that can be attached to runs’
- No tool was selected. In other words, the agent decided not to use the web_search tool or the search_langsmith_docs tool and come up with an answer purely based on the data it was trained on.
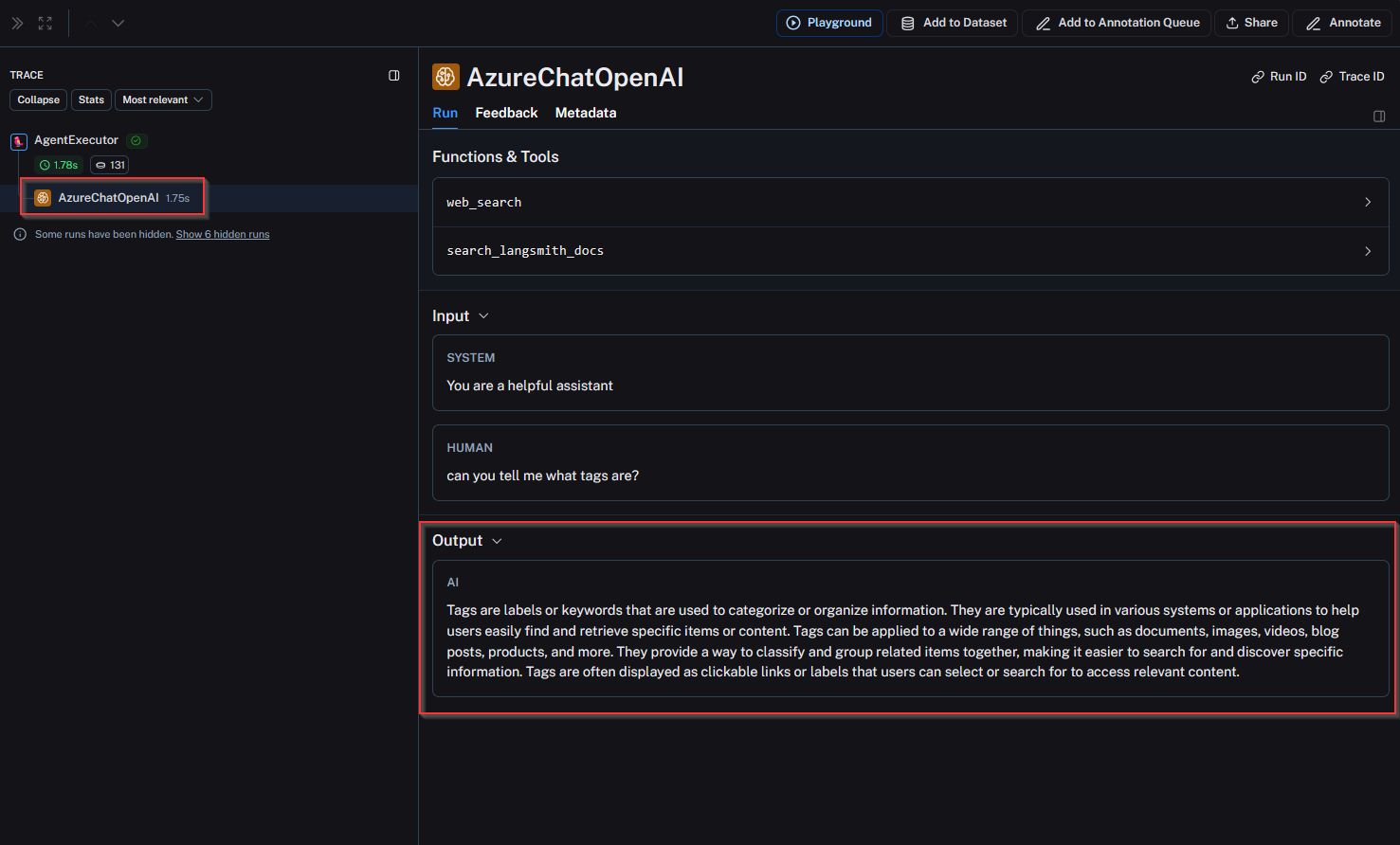
It seems since the input from the user was not explicit, the agent did not select a tool, therefore, relying on the data the LLM was trained on. This data will not be up to date with the LangSmith documentation.
Let’s contrast with the query ‘using the langsmith docs, can you tell me what tags are?’, and we can see the agent actually selected the search_langsmith_docs tool and was able to retrieve some relevant information from ChromaDB via a RAG pipeline:
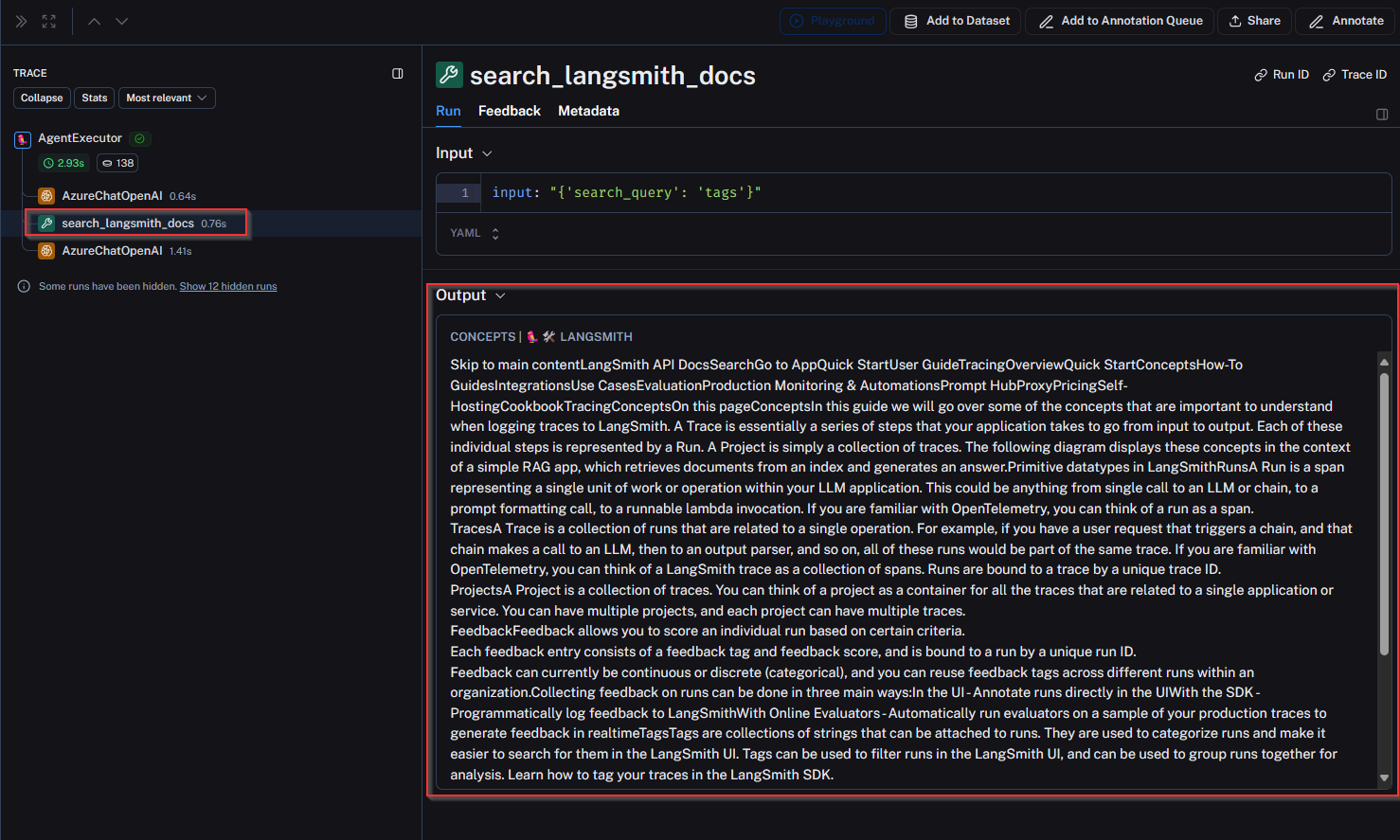
Some next steps could be working with the user on how to use effective prompt engineering techniques, or abstracting that from the user in the software by leveraging a methodology such as the MultiQueryRetriever to rewrite the input in a few different ways to optimize for RAG.
Soliciting Feedback From Users ✅❌
LangSmith can also be leveraged to capture feedback from the users. The most basic implementation of this would be a thumbs up/thumbs down rating system that is exposed at the end of an interaction with an LLM. LangSmith has an example of this using streamlit.
To demonstrate this, I have manually annotated a run and filtered by it:
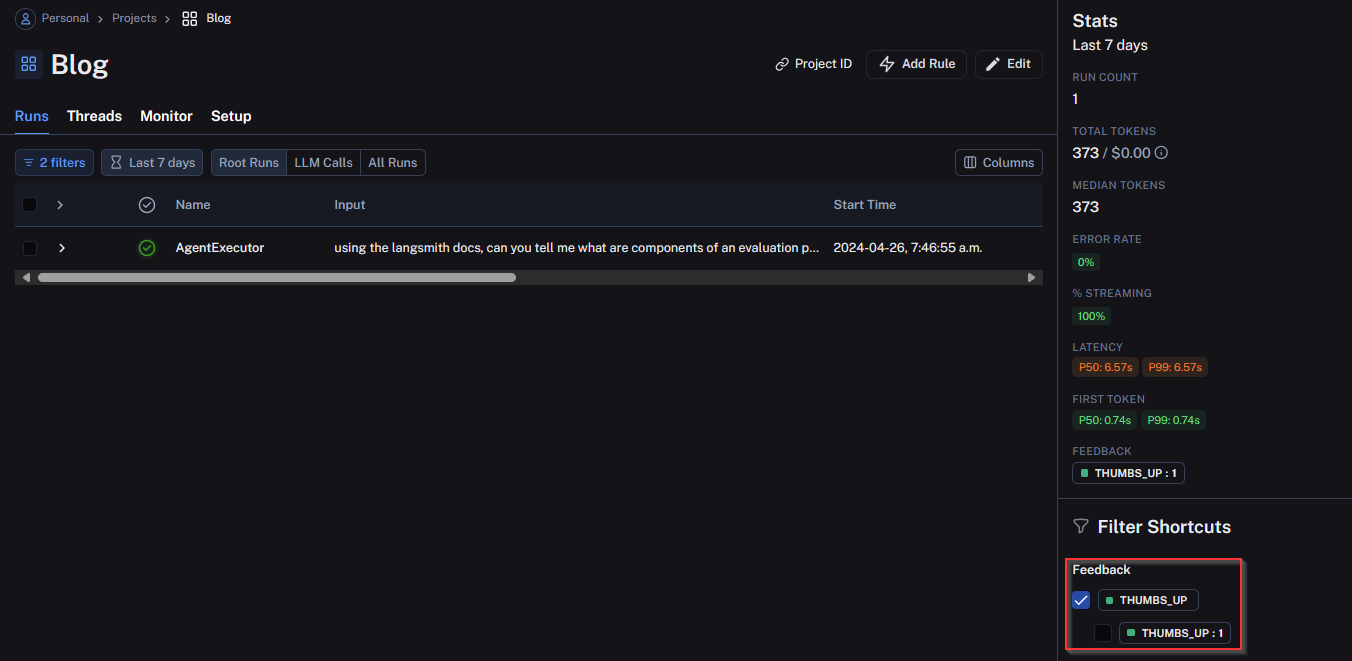
As we will see in the next section, this feedback can be collected into a dataset for fine-tuning operations.
Fine-Tuning 🔨
Building off of the solicitation of user feedback, and seeing we can filter the feedback, what we can do is take the inputs and outputs of those runs in LangSmith and add them to a dataset.
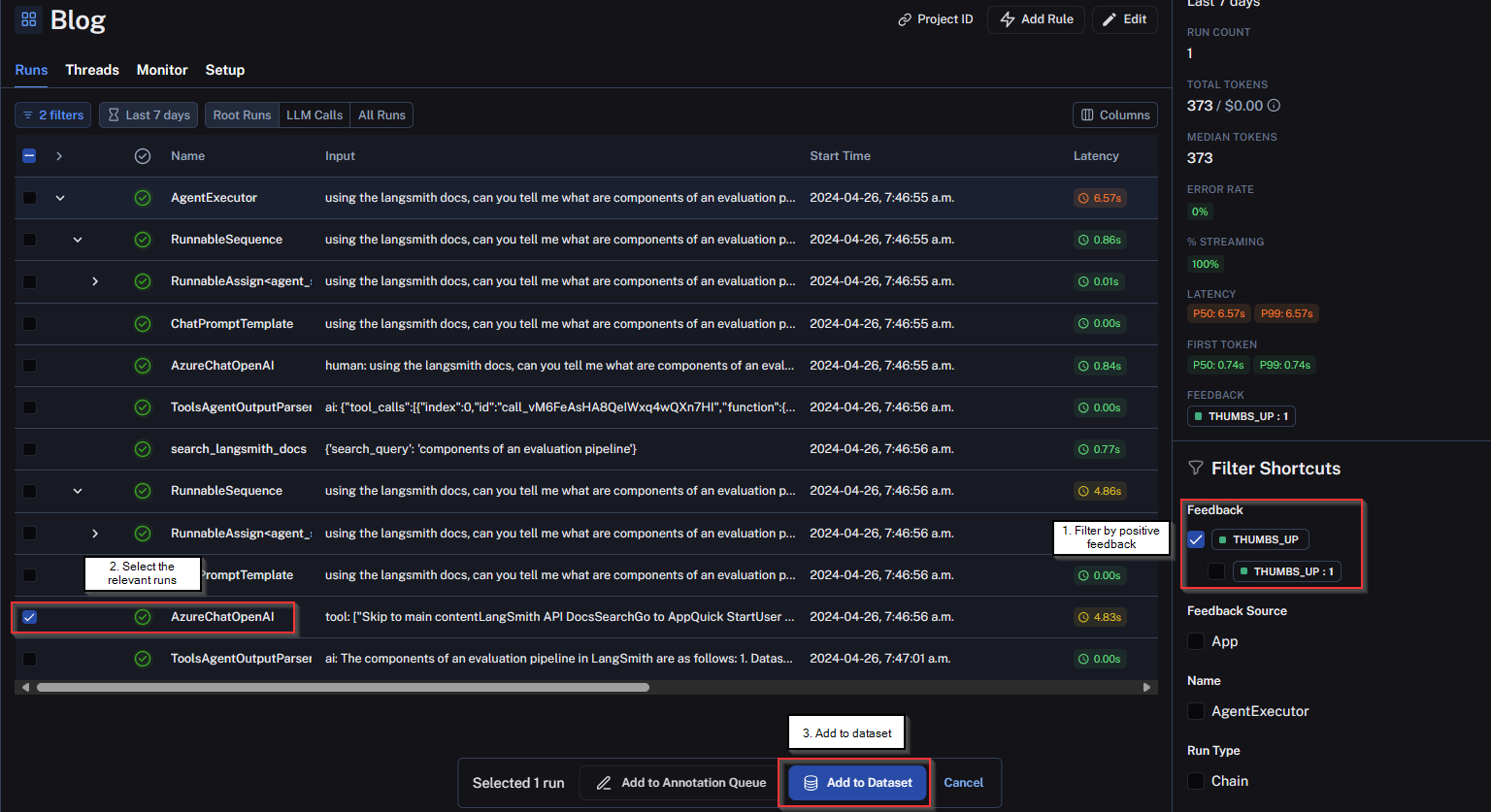
Subsequently, you can export the same dataset as a JSONL file, which can then be uploaded to Azure OpenAI to fine-tune a model.
The act of fine-tuning is heavily supported by papers/blogs like what LangChain describes here underscoring both cost savings and performance enhancements. This feature in LangSmith facilitates seamless data collection and fine-tuning of models.
Conclusion
Through my experimentation with LangSmith, I’ve found it to be a valuable tool for streamlining DevOps processes in the development of GenAI-enabled applications. While we’ve only scratched the surface of its potential, I’m optimistic about its ability to enhance the development lifecycle.
LangSmith boasts an active community, and its official YouTube channel, regularly shares updates and tutorials, fostering a supportive environment for users.
As we navigate the complexities of integrating GenAI into our applications, it’s essential not to overlook foundational principles like DevOps. LangSmith offers insights into critical aspects of monitoring, coding, and testing within this framework, addressing challenges such as tracing unexpected responses and managing complex AI-driven systems effectively.
Thanks for reading.