
🚀🔬 GenAI App Development with MLflow & Databricks

I have started digging into MLflow on Databricks, specifically how it can help us develop Generative AI applications. As the interest has grown internally to leverage generative AI, specifically agents, to complement a few existing use cases, I have been seeking how we can leverage the tooling in Databricks to its fullest capabilities.
A challenge we are having with many of our GenAI apps is getting them out of our development environment and into production. We have been a bit bullish about deploying apps into production and we have end users leveraging many of them, but there are gaps, especially on the GenAI side of things. Namely, it boils down to how we measure the quality of the apps we are deploying and improve them based on those metrics.
This blog is dedicated to my initial findings with MLflow on the Databricks platform.
Enjoy! 😀
🤖 Challenges Developing GenAI Apps
From my experience building these apps, the challenges I have faced have largely been data engineering and a bit of an integration problem. To maximize the value of GenAI in your company, the application you’re building needs access to your enterprise data. If the data is not loaded into a central place that is monitored for quality and governed, this makes the job of building agents and GenAI applications more difficult.
For example, as we were building our Lakehouse platform on Databricks, we started to have use cases pop up that were effectively RAG-focused. We were very early in learning how to leverage LLMs, and we jumped at any “chat over your data” use case to get our feet wet.
We were landing data from a SharePoint site into the raw layer in our lake. To get this data into a spot where we could perform RAG on it, we needed to perform a bunch of steps and answer a lot of questions:
Key Steps:
- Chunking: What chunking strategy will I select based on my documents?
- Embeddings/Vectors: What embedding model will I use to vectorize the chunks?
- Retrieval: What retrieval strategy will I use to optimize the results returned from the vector database?
- Generate: What LLM should I use to generate the output to the user?
We were also using an external vector database (Azure Search) which existed outside of our Databricks environment. This was effectively a copy of our data from the lake, which added complexity around updating it as new files landed from SharePoint, securing it, and integrating it with our app development stack.
Once we release an initial version, how do we start capturing feedback and use that to inform future releases?
The point is, there are lots of moving parts just to get an initial version going.
Databricks captures the continuous improvement cycle very well in the below diagram:
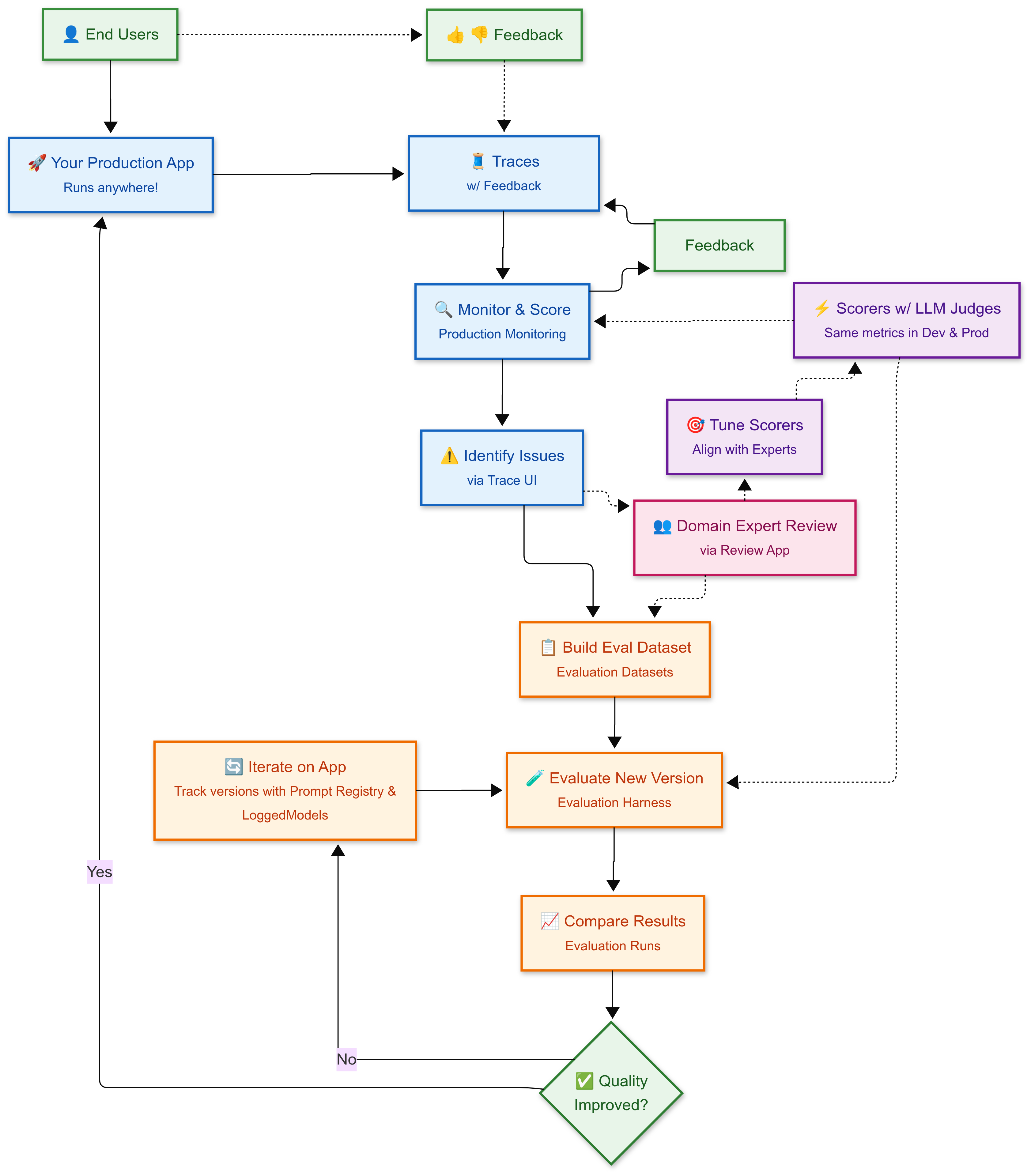
The diagram helped me visualize how the improvement cycle could look, but how does this work in practice?
❓ How Does MLflow on Databricks Help?
Building GenAI apps can introduce some interesting challenges into your software development. Unlike your software throwing an exception (ie: a failure), things like hallucinations, where the app returns wrong information and could give the end user the impression of the app ‘working’ when in reality that is not the case. The potential inputs to GenAI apps are generally endless.
Due to some of these factors, traditional testing practices for software don’t necessarily apply here. In traditional software testing, you have defined inputs as well as expected outputs you could test against to see if your function behaved as expected.
Given the vast nature of potential inputs for a GenAI app, this gets much harder to test.
This is where MLflow could be a good fit.
Based on my understanding so far, MLflow helps make your GenAI apps observable, testable and versionable. It also adds in the ability to capture human feedback about the output of your app.
I have only started digging into this but I am already excited at the potential. The documentation calls out that domain expertise is required to assess quality. I could not agree more with this statement.
We have this problem in our environment today. End users give us feedback and we have trouble filtering it back into the application lifecycle to drive improvements. We’ve started integrating our agents/apps with Genie in Databricks, combing through logs, and adding recurring queries to the context of the Genie room to improve query writing. While this approach helps, it is demanding on the dev team to capture, process, and act on feedback and it’s difficult to measure the impact of changes beyond anecdotal user claims.
This is where MLflow claims to help streamline the feedback loop.
MLflow’s Review App surfaces complete conversations so domain experts can spot issues. The intuitive interface allows non-technical experts to review app outputs without needing to understand code or complex tooling.
You can also scale domain expert feedback by using expert labels from a handful of traces to create custom LLM judges. These judges learn from expert assessments, allowing you to automatically evaluate the quality of iterations and production traffic without requiring human review for every response. This not only reduces the burden on the development team but also helps ensure that improvements are measurable and consistent over time.
I am pumped to dig into this more over the coming months!
LangGraph 🤝 Databricks
To get my head around how this works in practice, we took an existing LangGraph agent that I wrote about in a recent blog called 🤖🛢️ Building a Scalable AI System for Midstream O&G Contract Intelligence. We upgraded it to interact with Databricks managed MCP servers, namely a Genie space. We decided to package our LangGraph agent using MLFlows ‘models from code’. I had not used ‘models from code’ before but it basically allows you to save your models as readable Python scripts, making development more transparent and debugging significantly easier.
Some of the immediate benefits we saw were around tracing, versioning, and the ‘feedback loop’. Lets dive into those in a bit more detail:
👁️ Tracing
Agents that can call n number of tools can be notoriously difficult to troubleshoot and monitor both from a development and operations perspective due to the sheer number of inputs the agent could receive. MLFlow traces allow you to drill down into different ‘processes’ that took place during an interaction. Here is an example of the type of information we can see in a trace when the user says ‘get me all the unique legal entities’:
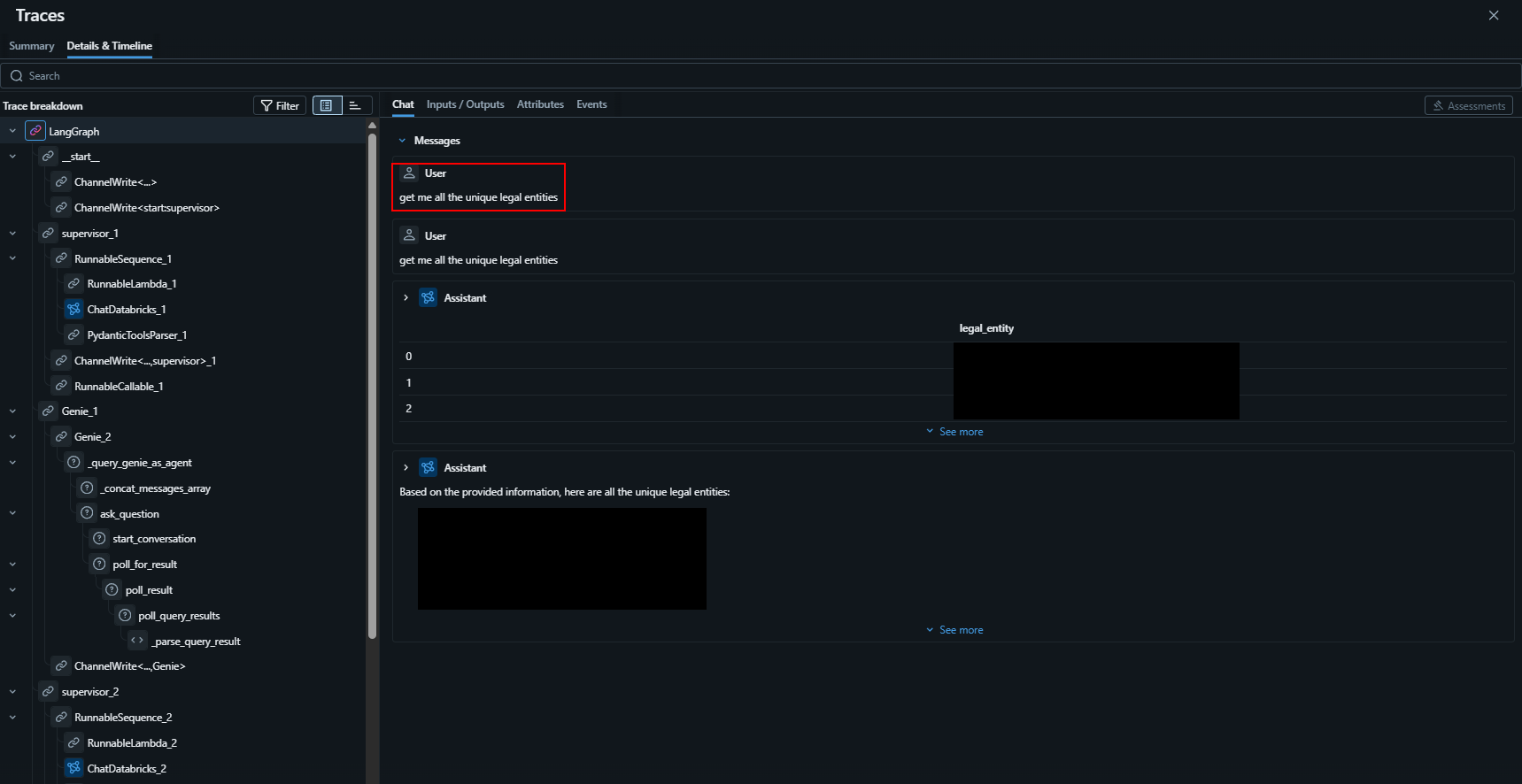
Note: I have blurred out a few areas in the above screenshot due to sensitivity.
As you can see in the above screenshot, we have a full trace of everything the agent executed following the user input.
We can even drill down into the Genie MCP call and see exactly the SQL query that was executed on the tables in that Genie space.
Now imagine as we start to add more tools to this agent how handy these traces will be for observability.
We have just started rolling this out to a few of our agents actively being used by end users, but I imagine this being very helpful when it comes to tracking down a particular interaction that netted less-than-ideal results.
🔁 Versioning
We have also started reaping some of the benefits of registering our “models” (i.e., agents) in Unity Catalog. We have run into scenarios with end users where we made a tweak to a tool description, a prompt, or swapped out an LLM for a different one, and it vastly impacted the experience of our end users.
Being able to manage model lifecycle in Unity Catalog has been a great experience so far as it has allowed us to update and augment our models and version it along the way. This process seems to be very much aligned with what Databricks talks about in their documentation around model lifecycle:
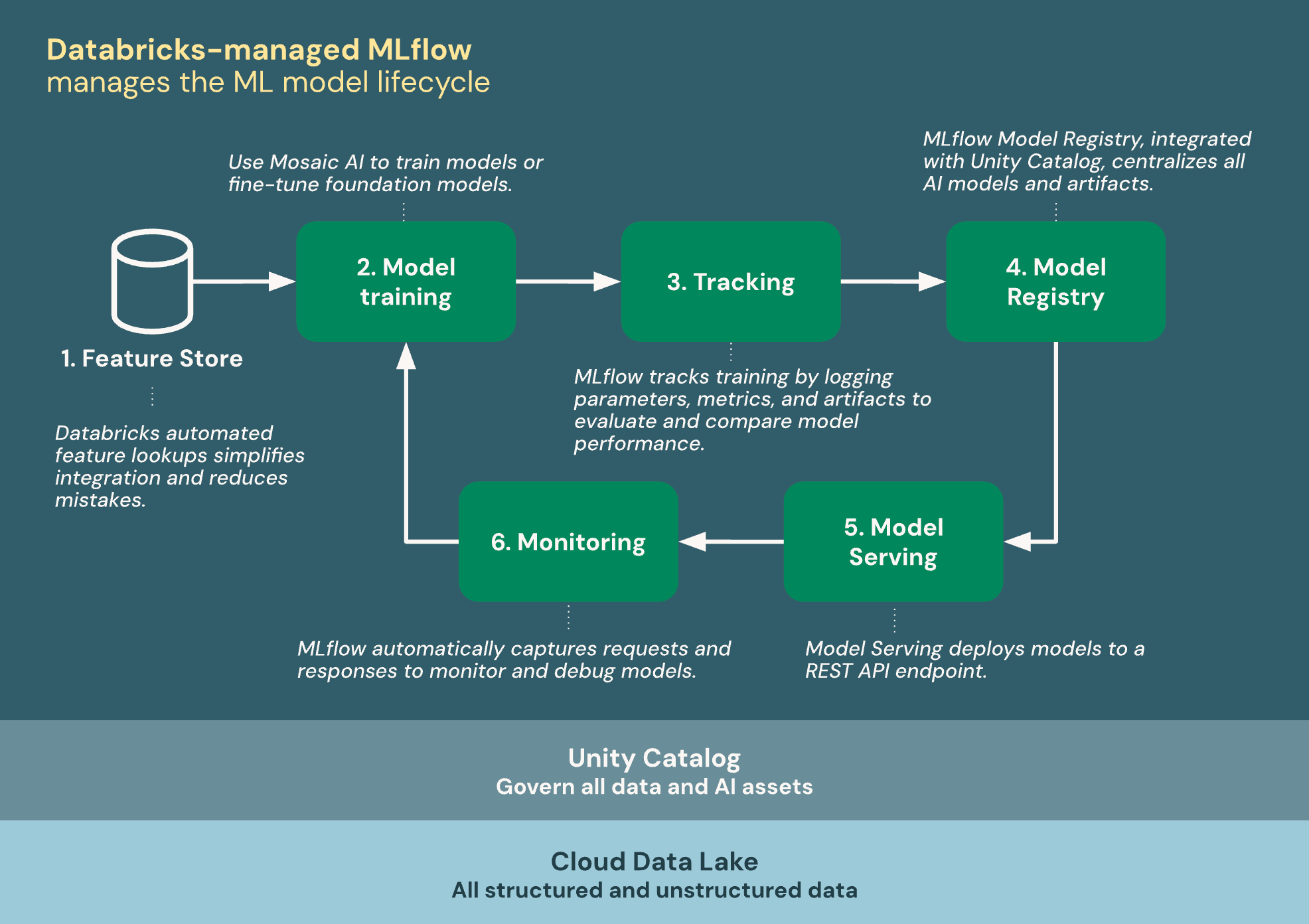
Once registered in Unity Catalog, we can serve the agent as a serving endpoint in Databricks.
The other feature we have started taking advantage of is the modification of traffic that is routed to our different model versions.
This basically means, we could configure the serving endpoint to send 60% traffic to our agent version 1, and 40% of the traffic to go to agent version 2 in Unity Catalog for example.
This reminds me very much of Azure App Service Slots, where you could deploy a new feature to a staging slot, split the traffic between the production slot and staging, monitor for errors, and swap them once you have confirmed there are no issues.
🗣️ Feedback Loop
Another challenge we had rolling these agents out to end users is when we get feedback on the agent, how do we build that into our agent lifecycle to update prompts, tools, retrieval, etc.? How do we even capture that feedback in a way that can be fed into these “improvement mechanisms”?
MLflow’s human feedback may be our answer.
We have started experimenting with collecting end-user feedback, and as we integrate our agent served in the Databricks model serving platform, we plan to integrate it with a Databricks App and bake in the code below to capture feedback from the end users on each interaction (i.e., trace):
import mlflow
from mlflow.entities.assessment import AssessmentSource, AssessmentSourceType
# Simulate end-user feedback from your app
# In production, this would be triggered when a user clicks thumbs down in your UI
mlflow.log_feedback(
trace_id=trace_id,
name="user_feedback",
value=False, # False for thumbs down - user is unsatisfied
rationale="Missing details about legal entities",
source=AssessmentSource(
source_type=AssessmentSourceType.HUMAN,
source_id="enduser", # Would be actual user ID in production
),
)
print("End-user feedback recorded!")
# In a real app, you would:
# 1. Return the trace_id with your response to the frontend
# 2. When user clicks thumbs up/down, call your backend API
# 3. Your backend would then call mlflow.log_feedback() with the trace_id
🎉 Conclusion
We plan to look at evaluations next. Typically, when we meet with stakeholders, we solicit a set of questions they are planning to ask. Plugging this list into MLflow’s evaluations will allow us to leverage LLM-as-Judge and more effectively benchmark the quality of the responses out of the gate.
I think we have just scratched the surface of what MLflow has to offer, but we are excited to learn more and see how it can help streamline the lifecycle of our ML models as well as our generative AI applications.
Thanks for reading 😀!