
How Confident Is Your AI? Understanding LLM Confidence Scores 🥇🤖

In a previous blog on Content Understanding I talked about the concept of ‘confidence scores’ where a number between 0-100 is generated to indicate how ‘confident’ and LLM is when generating a response.
Content Understanding exposes this confidence score property OOTB when processing documents through its service. This got me thinking, how do these confidence scores get generated and how would I implement it myself and integrate it into my LLM applications?
I decided to dive into the world of log probabilities to help understand this more.
Let’s start by understanding the math behind log probabilities. How exciting!
What is a Log Probability 🤷♂️
When we ask a large language model (LLM) a question, it doesn’t just randomly pick words. Instead, it assigns each possible word a probability based on how likely it is to fit in the sentence. But rather than working directly with these probabilities (which range between 0 and 1), LLMs often use log probabilities—the logarithm of the probability.
For example, imagine asking an LLM:
“What is the capital of Montenegro?”
| Word | Probability | Log Probability | Position on Scale |
|---|---|---|---|
| Podgorica | 0.98 | -0.02 | 🟢 Far right (most likely) |
| Belgrade | 0.01 | -4.6 | 🟡 Middle left (unlikely) |
| Naboo | 0.000001 | -13.8 | 🔴 Far left (LLM is sure this is wrong) |
Since Podgorica is almost certainly the correct answer, the LLM assigns it a high probability (0.98) and a log probability close to zero (-0.02). On the other hand, Belgrade, which is incorrect but geographically nearby, gets a much lower probability (0.01) and a log probability of -4.6. Naboo, a fictional place from Star Wars, has an extremely low probability (0.000001) and a highly negative log probability (-13.8), meaning the LLM is highly confident it should not be the answer.
Why Use Log Probabilities?
Log probabilities are useful for several reasons:
✅ Avoiding Small Number Issues – Raw probabilities can be tiny (like 0.000001), which can lead to numerical precision problems in computers. Logarithms turn these small values into manageable numbers.
✅ Simplifying Calculations – When predicting a sequence of words, an LLM needs to multiply probabilities. Logarithms turn multiplications into additions, which are faster and easier to compute.
✅ Improving Comparisons – It’s easier to compare log probabilities than raw probabilities because they are more evenly spaced on a scale.
So, the next time your AI confidently completes your sentence, remember, it’s not just guessing! It’s crunching log probabilities at lightning speed to give you the best possible answer. 🤖⚡
How to Get Log Probabilities in Practice ⚙️
Now that we have covered the theory, let’s apply log probabilities to structured data extraction using OpenAI’s API. Imagine we want to convert natural language into a structured format like a calendar event. Along with the extracted data, we’ll also get log probabilities, which allow us to assign confidence scores to each field.
The Problem 📌
Given this input:
Alice and Bob are going to a science fair on Friday.
We want the model to extract:
-
Event name: Science Fair
-
Date: Friday
-
Participants: Alice, Bob
…but we also want to measure how confident the model is about each extracted value.
Implementation 🏗️
The full code can be found in this notebook where I have included some documentation to step through the code. Here is a high-level breakdown:
-
Generate a Structured Response: Use OpenAI’s API to extract structured data with logprobs=True, ensuring token-level probabilities are returned.
-
Extract & Process Log Probabilities: Token-level log probabilities are converted into standard probabilities. Related tokens are aggregated to compute confidence scores for each extracted field.
-
Map Confidence Scores to Extracted Data: Each structured field is matched with its computed confidence score. Nested fields (if present) are handled separately to maintain accuracy.
-
Save Results: The extracted data and confidence scores are written to a CSV file for easy analysis.
The CSV results will look something like this:
Field,Value,Confidence Score
name,Science Fair,94.75%
date,2023-10-06,29.87%
participants,"[""Alice"", ""Bob""]",100.00%
We will leverage this same CSV in the next section to step through a real-world use case for confidence scores.
This approach provides not just structured data but also a transparent measure of the model’s confidence in its predictions! 🚀
How can these confidence scores be leveraged downstream of the LLM generation? Let’s go over a few use cases to see the potential for a feature like this.
Use Cases 🤖
By leveraging log probabilities, we can convert them into intuitive confidence scores that enhance data presentation and decisionm making.
Now that we can extract these confidence scores, we can leverage them downstream to aid our end users that are looking at the data the LLM extracted. In Power BI, for instance, we can create a conditional formatter to mark the data as green, yellow, or red depending on the confidence score:
🟢 High Confidence (70-100%) – Reliable extraction, likely accurate.
🟡 Medium Confidence (50-70%) – Needs review, may contain minor errors.
🔴 Low Confidence (0-50%) – Potentially inaccurate, requires verification.
Here is what the previously extracted CSV from the calendar example above looks like in PowerBI with conditional formatters:
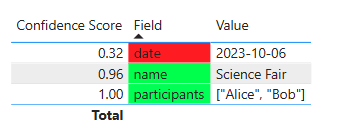
I think this really improves the end user experience. LLMs are prone to make mistakes and this makes it clear where the potential gaps are in the data and helps users quickly assess data reliability and take necessary actions.
I have worked through use cases where we had to process thousands of contracts through a structured output parser and the end user wanted to view that data in PowerBI. Exposing the confidence score gives end users the confidence to scan the report by trusting green values while focusing validation efforts on yellow and red ones.
Another use case for confidence scores is incorporating a human-in-the-loop (HITL) agent when the confidence falls below a certain threshold. Let’s say, 60%.
In this approach, an automated workflow processes structured data extraction as usual, but when an LLM returns a confidence score below 60%, the system flags the entry for manual review. A human reviewer can then verify or correct the extracted information before it moves downstream into reports or decision-making systems.
This method balances automation with accuracy:
-
High-confidence (≥60%) extractions flow through automatically.
-
Low-confidence (<60%) extractions trigger a review process.
This is especially useful in contract analysis, regulatory compliance, and financial document processing, where errors can have significant consequences. By integrating a human reviewer into the pipeline, organizations can reduce risk while still leveraging AI-driven automation.
Conclusion 🏁
Understanding log probabilities provides a deeper level of transparency in LLM-based applications. By leveraging token-level probabilities, we can quantify how confident the model is in its structured outputs. This is crucial for use cases where accuracy and reliability matter.
In this post, we explored:
✅ How log probabilities work and why they’re useful.
✅ How to extract structured data with OpenAI’s API.
✅ How to compute confidence scores for each field.
I want to extend a huge thanks to the VATBox llm-confidence project. Their implementation of log probability processing was incredibly helpful in understanding how to apply this in Python. 🚀
By integrating confidence scores into structured extraction, we gain an additional layer of interpretability, helping us build more trustworthy AI applications!
Thanks for reading 😀