
Guiding Generative AI Bots 🤖 with Semantic Router 🛣️

The more I have experimented with Generative AI applications, the more I have been puzzled on how to effectively roll out and ‘productionize’ agentic workflows where multiple steps, document retrievals, and tasks are involved. There have been many emerging approaches to solving this problem such as the ReAct framework but I have found frameworks like this to be slow and difficult to ensure deterministic outputs.
I have experimented with frameworks such as AutoGen, LangChain, and Semantic Kernel, but have struggled to create LLM powered applications that I felt comfortable deploying to production. I have run into things like ‘gratitude loops’ where the agents get caught in a loop of thanking each other for completing a task. While this being amusing, this has made me very cautious when deploying these LLM agents into a production environment.
In this blog, I wanted to touch on an alternative approach I stumbled upon that I think can help ensure more deterministic outputs with applications that leverage LLM’s. That approach leverages something called Semantic Router and I am experimenting with it right now in a few use cases I am working through.
What is Semantic Router?
As described in the documentation, ‘Semantic Router is a superfast decision-making layer for your LLMs and agents.’ and takes advantage of semantic similarity and vectorization to help increase the speed and accuracy of decisions. These ‘decisions’ have generally been left to agents and frameworks like ‘ReAct’ to sort out and like mentioned above, has it’s challenges.
I have been impressed so far with the speed and accuracy a framework like Semantic Router helps facilitate.
Example
Semantic Router is a PyPi package that can easily be installed on your machine to test out.
Semantic router has the concept of ‘routes’ and ‘utterances’ where you define phrases, questions, comments etc. as examples to help guide the framework when to use one route over the other. Let’s demonstrate this in action.
First, let’s create and activate a python virtual environment and install dependencies. Note, the requirements.txt for this code can be found here.
python -m venv venv
venv\scripts\activate
pip install -r requirements.txt
Now that we have our environment setup, lets start digging into the framework. In the below code, we define two routes.
-
A Small Talk Route
-
A Product Questions Route
Each route has an array of what the framework calls ‘utterances’ which are then vectorized for use downstream when determining what route to chose based on input.
# Import Semantic Router Libraries
from semantic_router.layer import RouteLayer, Route
from semantic_router.encoders import AzureOpenAIEncoder
import os
from dotenv import load_dotenv
load_dotenv()
#Define a small talk route
small_talk = Route(
name="small_talk",
utterances=[
"Hey, how are you?",
"How's it going?",
"Nice weather today"
],
)
#Define a product route
product_questions = Route(
name="product_questions",
utterances=[
"Tell me about the products you offer",
"What does a keyboard cost?",
"What does a mouse cost?"
],
)
Now that we have defined our routes, lets test them out. I am going to use Azure OpenAI’s text-embedding-ada-002 model for vectorizing the utterances and input.
#Bring in the routes
routes = [small_talk, product_questions]
#Define embeddings model to leverage
encoder = AzureOpenAIEncoder(api_key=os.getenv("AZURE_OPENAI_API_KEY"), deployment_name="embeddings", azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"), api_version="2024-02-15-preview", model="text-embedding-ada-002")
rl = RouteLayer(encoder=encoder, routes=routes)
#Send sample input to the router
print(rl("Hello there").name)
print(rl("What products do you have?").name)
Having a look at the output from the two print statements at the bottom, we get the following:

Breaking it down, semantic router was able to determine the input “Hello there” should be sent to the small talk route and “What products do you have?” should be sent to the product route.
If we were to contrast this with an approach using ReAct, the act of selecting the right tool for the job would be purely left up to the agent to decide. Where I think something like Semantic Router could be leveraged is creating well defined routes for your expected inputs, and have some if/else logic to execute respective logic depending on what route is selected. For instance, take the below PseudoCode as an example to articulate the if/else logic I mentioned:
def semantic_layer(query: str):
route = rl(query)
if route.name == "small_talk":
# Execute said logic
elif route.name == "product_questions":
# Execute said logic
else:
pass
return query
Each route would trigger a different set of logic in your application. So how does this fit into the broader ecosystem of GenAI tools such as LangChain? Let’s explore that in an example.
A Practical Example
Like I mentioned at the start of the blog, frameworks like ReAct, while useful, are slow and I think increases the chance of an agent making a ‘poor’ choice. What if we could leverage a framework like Semantic Router to first determine user intent and filter down to a specific workflow to reduce the amount of ‘tools’ an agent would have access to?
I have been testing this out in a few of my apps and I have found Semantic Router to not only be faster than frameworks like ReAct, but also more precise in selecting the right tool (or in this case, route) for the job.
LangChain 🦜& Semantic Router 🛣️
To walk through an example with LangChain, lets pretend we are a company that sells keyboard’s and mice for purchase. We have exposed a chatbot via our public facing website and want to ensure more deterministic outputs.
Let’s get started with defining routes for small talk, keyboard product questions and mice product questions.
from semantic_router.layer import RouteLayer, Route
from semantic_router.encoders import AzureOpenAIEncoder
from langchain import hub
from langchain_openai import AzureChatOpenAI
from langchain.agents import AgentExecutor, create_openai_tools_agent
from langchain_core.tools import tool
import os
from dotenv import load_dotenv
load_dotenv()
# Define small talk route
small_talk = Route(
name="small_talk",
utterances=[
"Hey, how are you?",
"How's it going?",
"Nice weather today",
"How's your day going?",
"What's up?",
"Did you have a good weekend?",
"How was your weekend?",
"Any plans for the evening?",
"How's work/school going?",
"What have you been up to lately?"
],
)
# Define keyboard questions route
keyboard_questions = Route(
name="keyboard_questions",
utterances=[
"What does a keyboard cost?",
"What do your keyboards look like?",
"Are your keyboards mechanical?",
"What colors do you offer?",
"Do you have any backlit keyboards?",
"Can I customize the keycaps?",
"Are your keyboards compatible with Mac?",
"Do you offer wireless keyboards?",
"Are your keyboards ergonomic?",
"Do you have keyboards with programmable keys?"
],
)
# Define mouse questions route
mouse_questions = Route(
name="mouse_questions",
utterances=[
"What does a mouse cost?",
"What do your mice look like?",
"Are your mice mechanical?",
"What colors do you offer?",
"Do you have wireless mice?",
"Are your mice suitable for gaming?",
"Can I adjust the DPI settings?",
"Are your mice compatible with Mac?",
"Do you offer left-handed mice?",
"Are your mice Bluetooth enabled?"
],
)
# Bring in the routes
routes = [small_talk, keyboard_questions, mouse_questions]
encoder = AzureOpenAIEncoder(api_key=os.getenv("AZURE_OPENAI_API_KEY"), deployment_name="embeddings", azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"), api_version="2024-02-15-preview", model="text-embedding-ada-002")
rl = RouteLayer(encoder=encoder, routes=routes)
Let’s add on to this by adding a few tools that an agent in LangChain can leverage to anwser the customers questions. For the purposes of the blog, I have just hard coded the return values for the tools, however, in an actual scenario, you could perform RAG on product documentation to get the information about the keyboard and mice you sell and expose those to agents as tools.
@tool
def keyboard_cost() -> str:
"""Used to get pricing information about keyboards"""
return "You sell keyboards for $75.95 each"
@tool
def keyboard_color_info() -> str:
"""Used to get color information about keyboards"""
return "Comes in black and white"
@tool
def mouse_cost() -> str:
"""Used to get pricing information about a mouse"""
return "You sell mice for $49.95 each"
@tool
def mouse_color_info() -> str:
"""Used to get color information about a mouse"""
return "Comes in black and white"
Let’s add some if/else logic to fire certain steps if a route is selected. Notice how in the below code, we leverage LangChains openai-tools-agent in both the keyboard_questions and mouse_questions route and instead of passing all tools to one ‘master’ agent, we only pass through the tools that are needed for that specific task (ie: route).
def semantic_layer(query: str):
route = rl(query)
if route.name == "keyboard_questions":
model = AzureChatOpenAI(api_key=os.getenv("AZURE_OPENAI_API_KEY"), azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"), deployment_name="gpt35_turbo", api_version="2024-03-01-preview")
prompt = hub.pull("hwchase17/openai-tools-agent")
tools = [keyboard_cost, keyboard_color_info]
agent = create_openai_tools_agent(model, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_executor.invoke({"input": query})
elif route.name == "mouse_questions":
model = AzureChatOpenAI(api_key=os.getenv("AZURE_OPENAI_API_KEY"), azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"), deployment_name="gpt35_turbo", api_version="2024-03-01-preview")
prompt = hub.pull("hwchase17/openai-tools-agent")
tools = [mouse_cost, mouse_color_info]
agent = create_openai_tools_agent(model, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_executor.invoke({"input": query})
else:
pass
return query
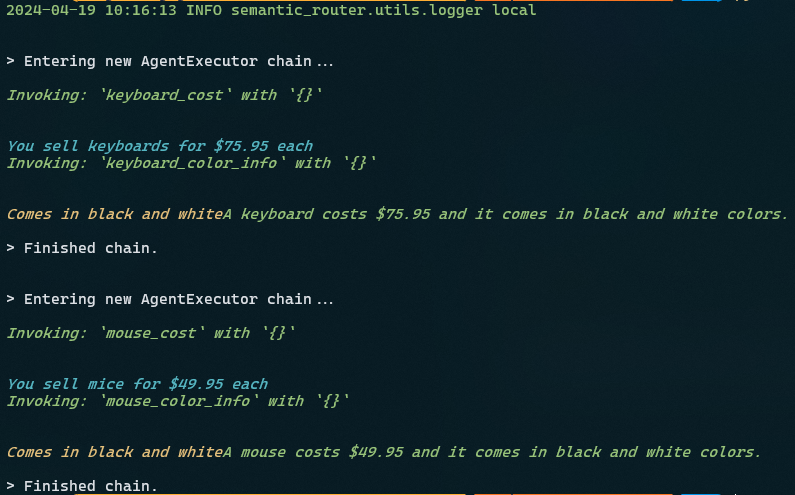
query = "What does a keyboard cost and what colors does it come in?"
semantic_layer(query)
query = "What does a mouse cost and what colors does it come in?"
semantic_layer(query)
I think this is helpful from the perspective of not providing the agent with too many choices in the form of tools. I have found having very specific agents for focused tasks, generally nets better results in the form of accuracy and speed.
Executing the above outputs the following results:
Conclusion
This blog discussed the challenges faced in deploying Generative AI applications into production and introduced Semantic Router as a potential solution for more deterministic outputs. By leveraging Semantic Router, developers can efficiently manage agentic workflows and ensure better decision-making. Through practical examples with LangChain, it’s evident that Semantic Router offers speed and accuracy in user intent extraction, leading to enhanced customer interactions.
The source code for all the above examples can be found here
Thanks for reading.