
🗺️🤖 Exploring Agent Bricks: Databricks’ New Approach to Building AI Agents
There were lots of exciting things announced at the Databricks Data + AI Summit, and I have been carving out time to start looking into them over the last few months.
One of the announcements I was most excited about was Agent Bricks! The reality is most data teams are not going to have the required skillsets to successfully build and deploy agents.
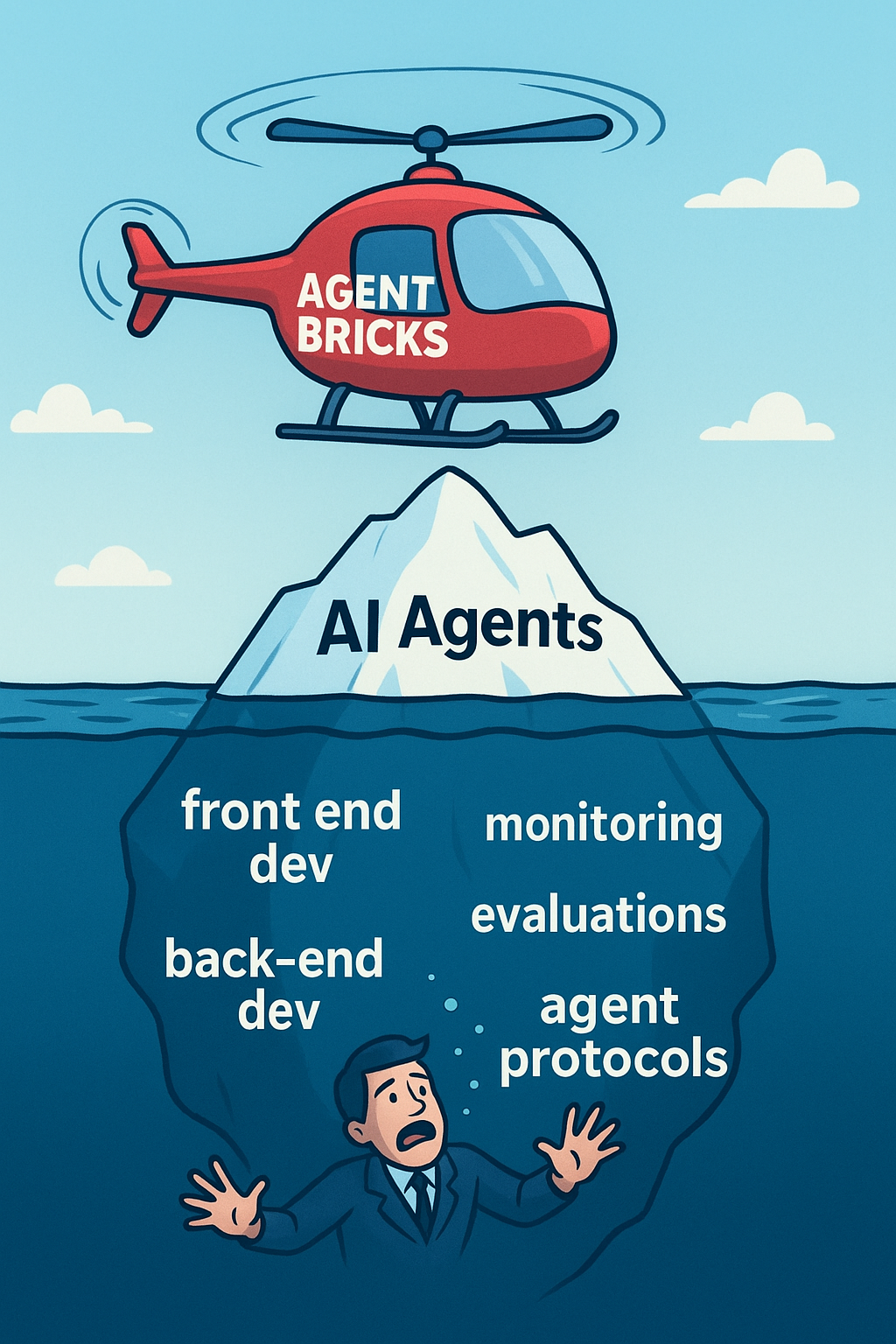
I recently saw a post on LinkedIn giving a reality check on AI agents.
‘AI Agents are NOT just a fancy UI over ChatGPT. They are deeply complex systems’!
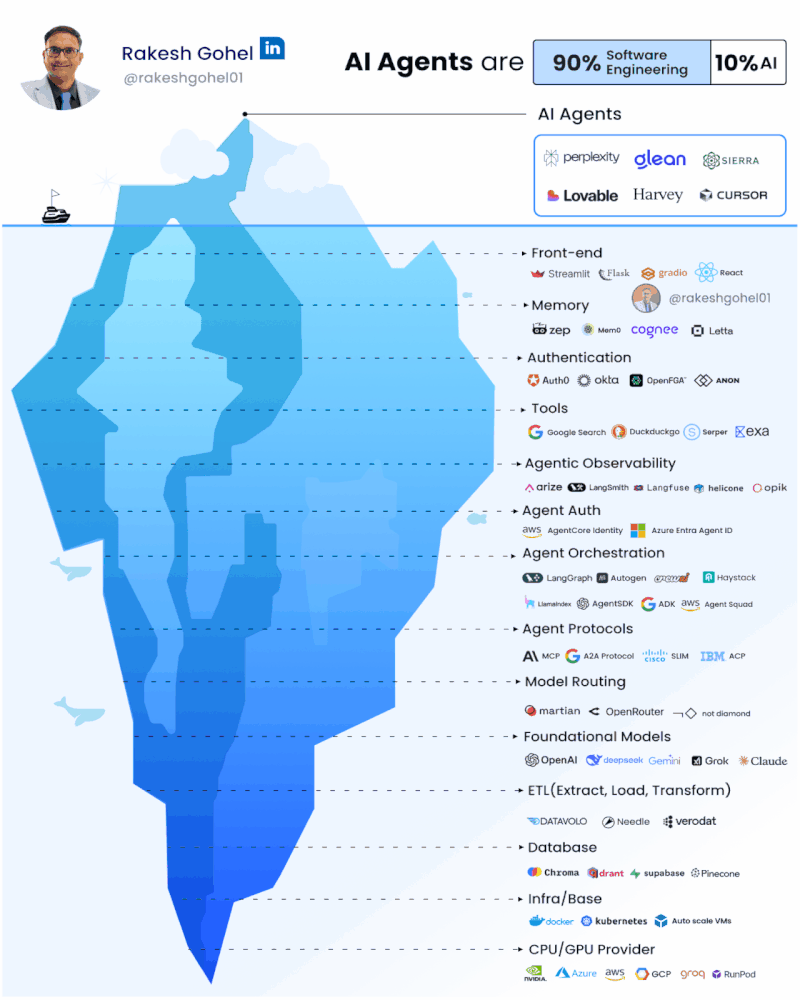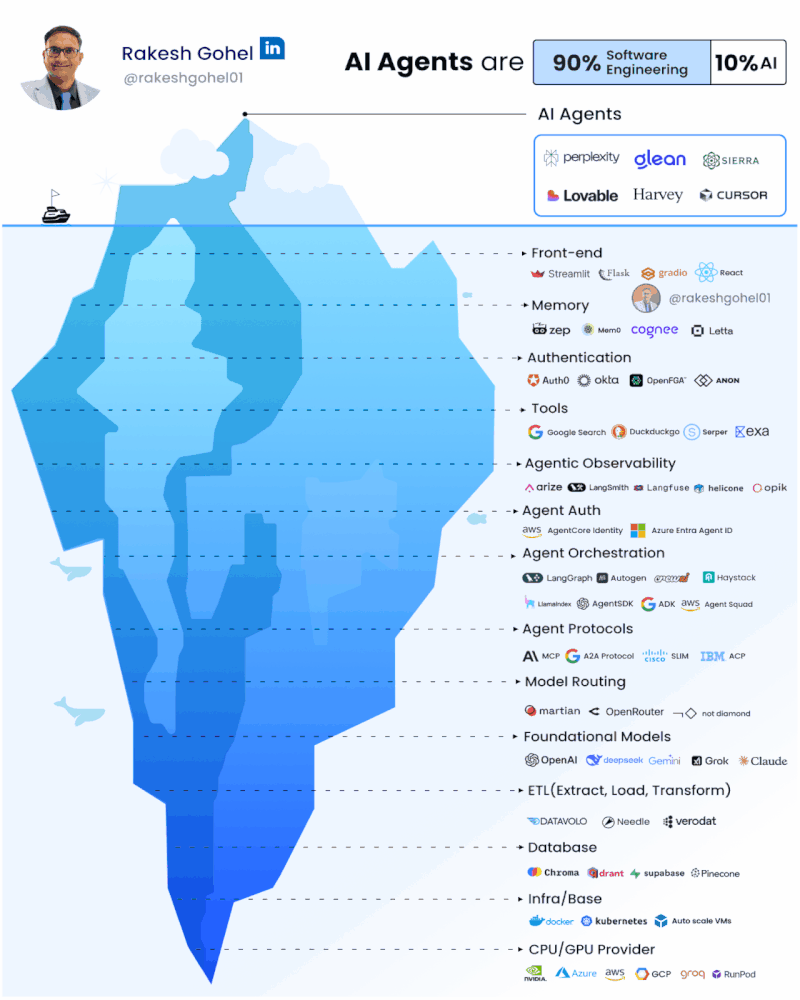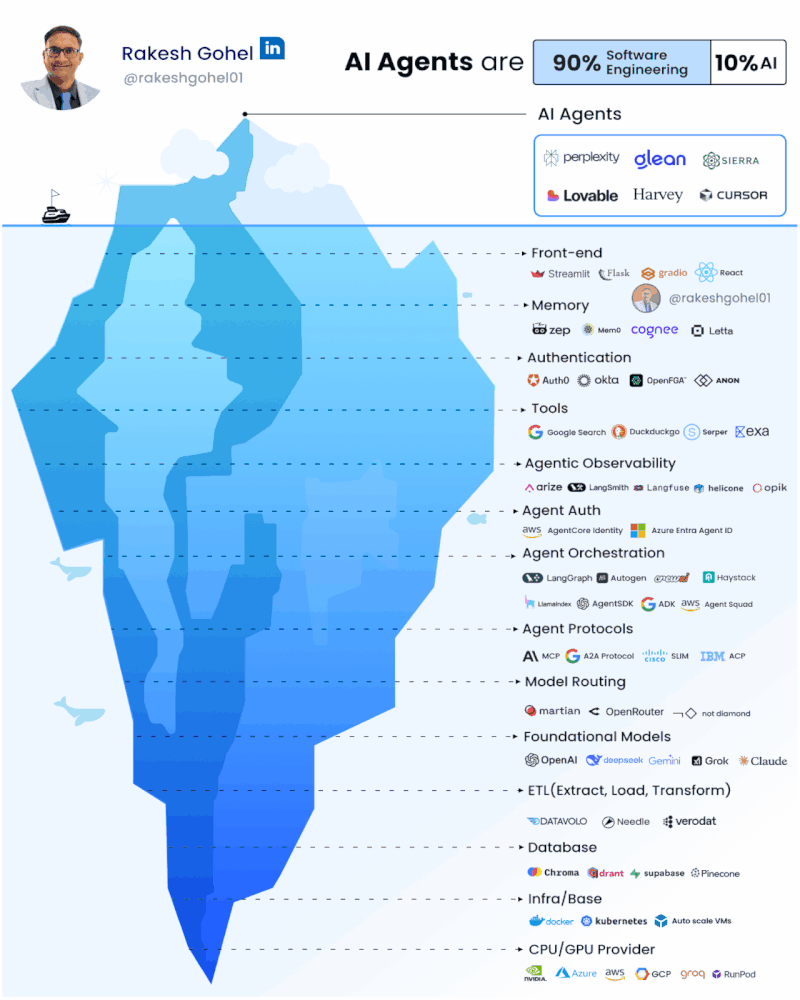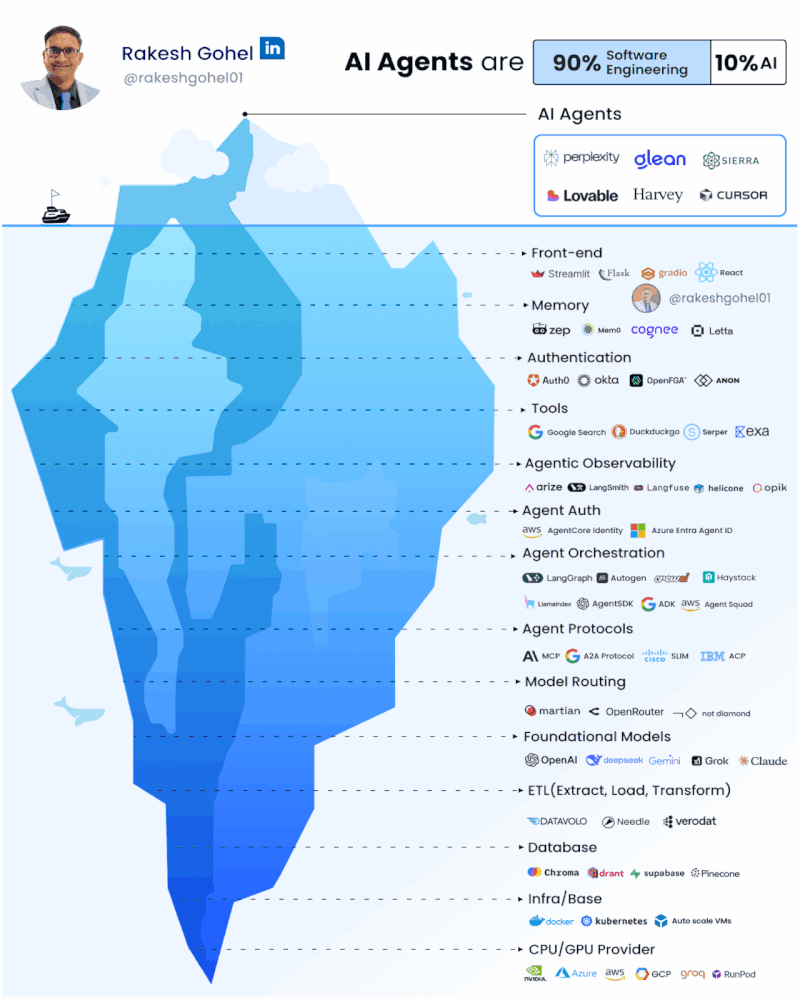
There’s a lot of buzz about AI agents, and they are far more than just chat interfaces or simple API wrappers. Building real AI agents means tackling complexity across the entire stack.
The skillset required to build agents is really more of a software engineer than a data engineer.
Although I have a blast leveraging the technology to craft my own agents through software, I appreciate it is a massive undertaking to roll out agents.
The Databricks Mosaic AI Research team has been doing some cool stuff in this space to help streamline this experience.
🤖🧱 Intro to Agent Bricks
“Agent Bricks streamlines the implementation of AI agent systems so that users can focus on the problem, data, and metrics instead.”
Building agents is hard. Like I talked about in my 🚀🔬 GenAI App Development with MLflow & Databricks, there are so many different steps and knobs to turn when building agents.
Everything from engineering your prompts, chunking the data to prepare for vectorization, selecting an LLM, the number of choices you need to make as a developer is overwhelming and makes iterations tedious and error-prone. Agent Bricks allows teams to focus on the use case and provide feedback to the agent to improve its quality through natural language.
Databricks talks about the concept of Agent Learning from Human Feedback (ALHF), which seems to be an internally developed method to help improve the quality of agents.
ALHF recognizes the difficulty of steering agent behavior based on feedback and has developed algorithms in Agent Bricks to take natural language feedback and translate it into technical optimizations. Pretty cool stuff! I was trying to find more documentation on ALHF to learn more but could not find any.
🤖 Types of Agent Bricks Agents
As of writing this blog, Agent Bricks supports a few different types of agents. Here are a few of the notable ones I have used:
Information Extraction
The information extraction agent enables you to transform large volumes of unlabeled text documents into structured tables with extracted information. This provides you the ability to structure unstructured data using an agent! In a recent blog called 🤖🛢️ Building a Scalable AI System for Midstream O&G Contract Intelligence, I detailed all of the steps required to structure unstructured oil and gas contracts.
Similar to the argument made above about the skillset required for building agents, this use case has an equally high barrier to entry. This is where I think the Agent Bricks information extraction agent can help streamline use cases like this.
The textbook use cases for this agent are things like:
- Extracting prices and lease information from contracts.
- Organizing data from customer notes.
- Getting important details from news articles.
This agent also leverages automated evaluation capabilities, including MLflow and Agent Evaluation. What that means for you is you can rapidly iterate on an agent and improve its quality and even reduce its cost. This assessment allows you to make informed decisions about the balance between accuracy and resource investment, which outside of Agent Bricks would be very difficult to orchestrate.
⚠️ Limitations
A few things to keep in mind if you’re considering the Information Extraction agent:
- Databricks recommends at least 1000 documents to optimize your agent. The more documents you add, the better the agent can learn and the more accurate your extractions will be.
- There’s a 128k token max context length for Information Extraction agents.
- Workspaces using Azure Private Link (including storage behind Private Link) are not supported.
- Workspaces with Enhanced Security and Compliance enabled are not supported.
- Union schema types are not supported.
Knowledge Assistant
This agent enables you to ask questions on your documents. The classic RAG use case. I have spoken in the past about how complicated RAG architectures can be, especially with all the knobs you can turn.
The textbook use cases for this agent are things like:
- Answer user questions based on product documentation.
- Answer employee questions related to HR policies.
- Answer customer inquiries based on support knowledge bases.
What sets Knowledge Assistant apart is how easy it is to improve the agent’s quality. You (or your subject matter experts) can give natural language feedback right in the UI. There’s a built-in labeling session workflow: add questions, send them for review, and the feedback gets used to optimize the agent.
⚠️ Limitations
Some practical considerations for the Knowledge Assistant agent:
- Databricks recommends using files smaller than 32 MB for your source documents.
- Workspaces using Azure Private Link (including storage behind Private Link) are not supported.
- Workspaces with Enhanced Security and Compliance enabled are not supported.
- Unity Catalog tables are not supported as data sources.
Multi-Agent Supervisor
This agent is most interesting to me as this is where I have spent most of my time with tools like LangGraph. Having experimented lots with stringing together multiple agents with many tools, I appreciate this is a very complex world.
The textbook use cases for this agent are things like:
- Provide market analysis and insights by searching across research reports and usage data.
- Answer questions about internal processes and automate a ticket backlog for it.
- Speed up customer service by answering policy, FAQ, account, and other questions.
⚠️ Limitations
A few gotchas to be aware of with the Multi-Agent Supervisor:
- Only agent endpoints created through Agent Bricks: Knowledge Assistant are supported.
- You can’t use more than 10 agents in a single supervisor system.
- Workspaces using Azure Private Link (including storage behind Private Link) are not supported.
- Workspaces with Enhanced Security and Compliance enabled are not supported.
🌍 Real-World Use Cases
We have been exploring a few use cases on the side. There is nothing in production currently, but here are a few Agent Bricks agents we have built out in dev and are actively exploring.
🕷️ Data Weaver Logs
The software we have built to help with our data engineering and AI workloads we have nicknamed Data Weaver! All of the jobs we run through Data Weaver get logged through our centralized logging abstraction called slogger.
slogger puts logs into a delta table in Unity Catalog, and we have leveraged this table to build a PowerBI dashboard for the support team to monitor for any errors or exceptions.
Having slogger send the logs to a delta table has other benefits as well, such as allowing us to integrate it with a Genie Space. The Agent Bricks Multi-Agent Supervisor can integrate very easily with a Genie Space, and this could enable our support team to explore logs using natural language to ask questions like:
- Which jobs failed in the last 24 hours, and what were the error messages?
- Did the Maximo extraction job complete successfully, and how long did it take?
- Who was the last person to run or trigger this job?
I wonder as the technology evolves if we could actually have the agent restart Databricks workflows via calling an MCP endpoint based on certain events in the logs, such as a failure?
📄 Contract Intelligence
I mentioned earlier that I really enjoy the process of building agents through software, but I also appreciate the upkeep required and the amount of complexity it introduces is large.
I wanted to test and see if the information extraction agent could help with a recent use case to assist with organizing contracts for a divestiture effort. This includes things like separating out NGL versus Crude contracts and identifying counterparties for sorting and filtering of contracts.
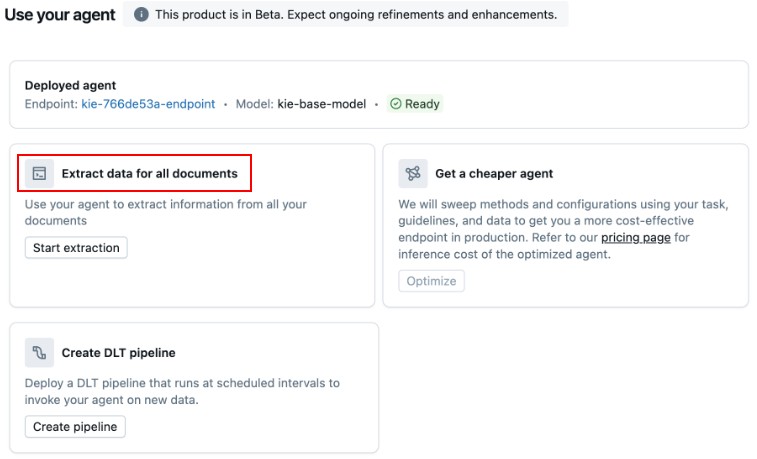
Agent Bricks provides an easy way to build and improve the agent where you can adjust the descriptions of the schema fields that you want your agent to use for output responses.
The act of using this agent becomes very simple since you can select the extract data for all documents option and it gives you a sample query to leverage ai_query to invoke your information extraction agent at scale against all your documents.
df = spark.sql("""
WITH query_results AS (
SELECT `text` AS input,
`path`,
ai_query(
'kie-883c7b08-endpoint',
input,
failOnError => false
) AS response
FROM (
SELECT `text`, `path`
FROM `catalog`.`schema`.`table`
LIMIT 40
)
)
SELECT
input,
path,
response.result AS response,
response.errorMessage AS error
FROM query_results
""")
display(df)
This was very handy for us since we can integrate this agent very easily into our Data Weaver software as a transform option engineers could invoke via their notebooks
🥳 Conclusion
It’s impressive how much complexity the Mosaic AI Research team has managed to hide behind Agent Bricks. Instead of wrangling with endless configuration and code, you can actually focus on what matters: solving real business problems and making improvements based on feedback.
Agent Bricks also opens the door for more people to experiment and try new ideas, even if they aren’t deep AI experts. I’m excited to see how this evolves and what new use cases show up as more teams get their hands on it. If you’re even a little bit curious about AI agents, Agent Bricks is definitely worth checking out.
I will say though this is both an exciting time and a frustrating time to be in tech. You can invest a lot of time building out software to solve a problem, and next thing you know, there is a new tool that solves that exact problem. I suppose it is just the nature of the industry.
Thanks for reading! 😀