
Chunking for RAG 🪓🤖

NOTE: On June 24th, I had the opportunity to speak at the Microsoft office on ‘Chunking for RAG’ with the goal of emphasizing the importance of data preparation for generative AI. This post follows up on that event to gather my thoughts on the topic, and I want to thank everyone who attended.
In this post, I aim to explore a topic often overlooked in building RAG pipelines: data preparation for generative AI, specifically focusing on chunking. By the end of this post, I hope to encourage everyone to reconsider their RAG pipelines and prioritize data preparation for retrieval.
This aspect parallels challenges in data engineering and data science. While everyone is eager for the exciting machine learning and data science aspects, the crucial data engineering work often gets neglected. Yet, it is essential for cleaning and preparing data to achieve successful outcomes. Generative AI is similarly affected—a “garbage in, garbage out” scenario where the quality of input data significantly impacts results.
This post will cover several key areas. First, we’ll delve into the foundational concepts of RAG: what it is and the problems it addresses. Second, we’ll discuss why we chunk documents for RAG and explore various strategies, detailing their respective advantages and disadvantages. I’ve open-sourced the repository for this discussion, titled chunking_for_rag
Let’s dive into it!
What is RAG? 🤷♂️
LLMs, while powerful, can sometimes provide outdated or inaccurate information because their knowledge is static and limited to their last training update. Retrieval Augmented Generation (RAG) addresses this by fetching current facts from external data sources, ensuring the generated content remains relevant and accurate.
It’s akin to equipping the LLM with a research assistant to swiftly retrieve the latest information as needed.
To illustrate how a basic RAG pipeline operates, refer to the diagram below:
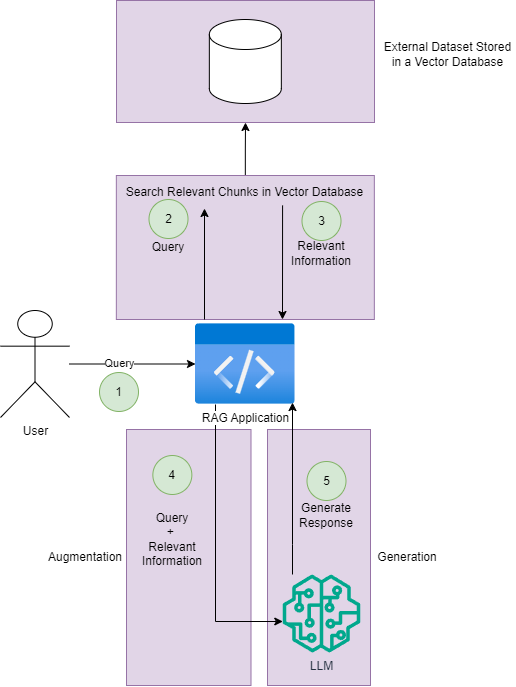
-
The user sends a query to a middleware or application that orchestrates the RAG pipeline.
-
The query data is forwarded to an external dataset (likely stored in a vector database) to locate the most semantically similar documents to the user’s question. This constitutes the “R” in RAG or the retrieval step.
-
Relevant information based on the user’s query is retrieved and returned to the RAG application.
-
The RAG application integrates the original query with the retrieved information into a prompt. This step is the augmentation (“A” in RAG).
-
Subsequently, this prompt is forwarded to an LLM to generate a response, representing the generation aspect (“G” in RAG).
RAG serves as an effective architectural pattern for grounding LLMs in data, thereby enhancing the accuracy of their outputs.
Why is Chunking Important? 🪓
Chunking is important for a few reasons. We will cover the three primary reasons why you want to chunk your documents prior to vectorizing them and upserting them into a vector database.
LLM’s have Limited Context Windows 🪟
LLMs have limits on the amount of text that can be included in a prompt at once, known as the context window. These context windows have expanded over time with new LLM releases. For instance, GPT-3 had a context window of 4097 tokens (about 3081 words). Newer models like GPT-4 have context windows of up to 128,000 tokens (around 96,000 words). This significant increase allows LLMs to process much more text. However, there are implications to this expansion, which we will discuss next in the post (ie: Signal to Noise Ratio).
Signal to Noise Ratio 🔊
The signal-to-noise ratio is crucial in understanding how well a language model (LLM) can extract information from a prompt. Essentially, the more irrelevant information (‘noise’) present in a prompt, the harder it is for the LLM to retrieve the relevant facts (‘signal’).
This concept is highlighted in the Multi Needle in a Haystack blog, where an LLM is tasked with extracting multiple facts from prompts of varying sizes (e.g., 1000 tokens and 120000 tokens).
The below diagram shows two different sized prompts:
-
1000 tokens (green)
-
120000 tokens (red)
On the X-axis, as the number of facts (needles) the LLM is asked to extract increases, and as the prompt size grows, the LLM’s ability to retrieve all the facts diminishes. This is evident when GPT-4 was asked to extract 10 facts from a 120,000-token prompt, where performance significantly degraded.
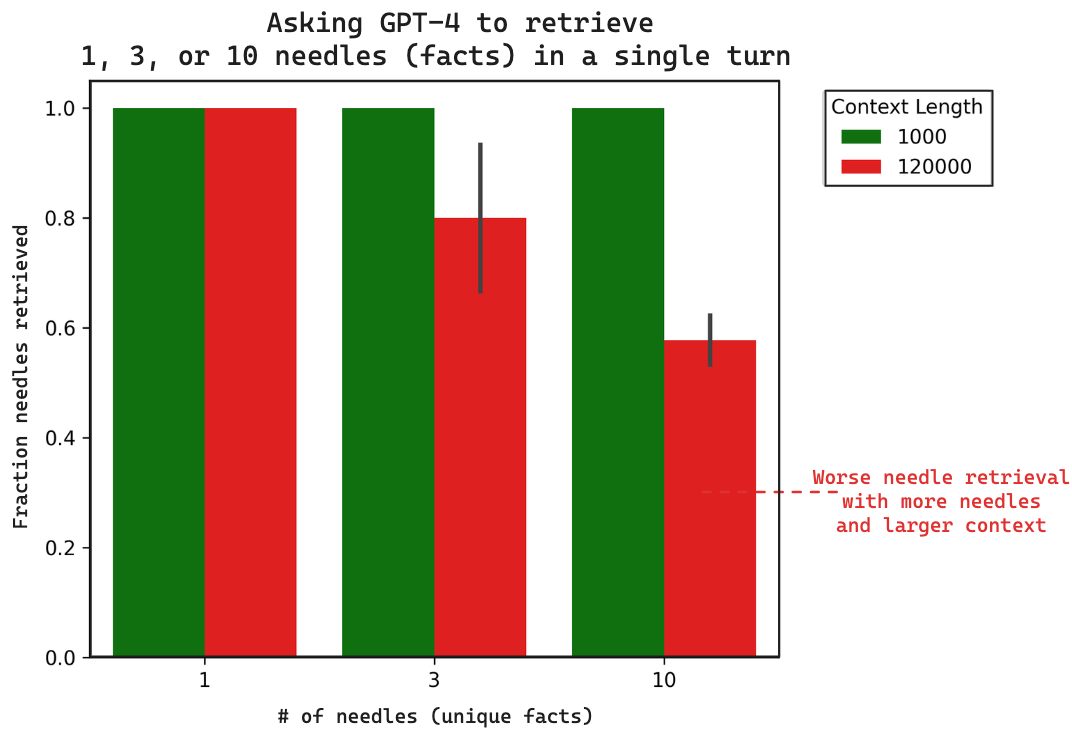
While improvements in LLM capabilities are expected over time, effectively chunking information to retrieve only the most relevant data based on the user’s query will yield the best results.
Reduced Cost 🤑
Although the cost of LLMs has been decreasing, it remains an important factor to consider when designing applications for scale. Relating to the signal-to-noise concept mentioned earlier, including too much irrelevant information in your prompt can unnecessarily increase costs. This highlights the importance of an effective chunking strategy. Only the relevant chunks should be retrieved and included in your prompt.
Chunking Strategies ♟️
When chunking your document for Retrieval-Augmented Generation (RAG), there are several strategies you can use:
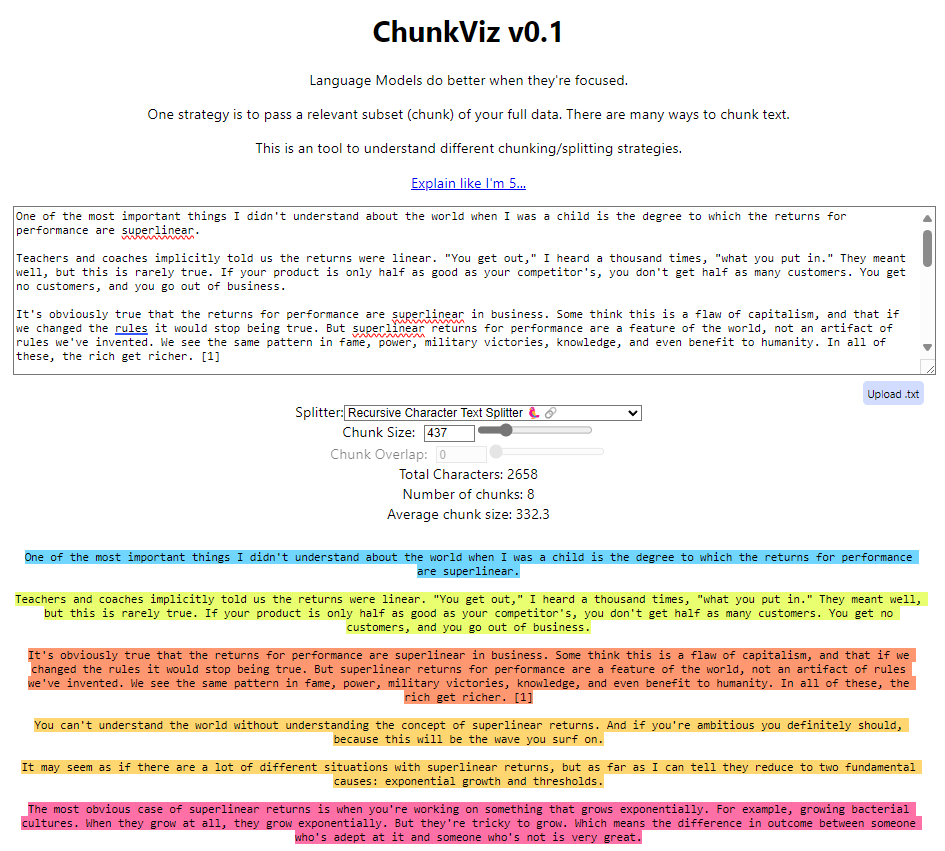
- Character Splitting: This is the most basic form of chunking as it does not consider the document’s structure. Character splitting involves dividing your text into chunks of a specified size without taking context into account. Key concepts include chunk size (the number of characters per chunk) and chunk overlap (the amount by which chunks overlap). Tools like ChunkViz can help visualize this.
Using ChunkViz, we can see the limitations of character splitting, such as cutting off information mid-sentence or even mid-word. For example, with a 181-character chunk size, highlighted sections show where context is lost due to this chunking strategy.

- Recursive Character This is a more sophisticated strategy that considers the document’s structure. Recursive character splitting attempts to chunk based on sentences and paragraphs, improving context retention. This method is particularly effective because documents are typically organized by paragraphs and sentences. In ChunkViz, this approach shows improved results as sentences and paragraphs are not split awkwardly.
- Document Specific Splitting: Sometimes the best chunking strategy depends on the document itself. For instance, in a practical example of chunking the “Book of News” for Microsoft Build 2024, we might use a document-specific strategy to chunk based on headers, ensuring effective retrieval based on the questions asked.
Chunking Considerations 💭
When it comes to chunking, there are several considerations to keep in mind:
-
Nature of the Content: What type of content are you indexing? Are you working with long documents such as articles or books, or shorter content like tweets or instant messages? The answer will influence which chunking strategy to apply.
-
User Query Expectations: What do you expect in terms of the length and complexity of user queries? Will they be short and specific, or long and complex? This consideration may inform how you choose to chunk your content to ensure a closer correlation between the embedded query and the embedded chunks.
-
Utilization of Retrieved Results: How will the retrieved results be used within your specific application? For example, will they be used for semantic search, question answering, summarization, or other purposes?
Reflecting on these questions will help you optimize your chunking strategy for your specific needs.
A Practical Example 👨💻
As mentioned earlier, I have open-sourced notebooks to demonstrate how significantly your chunking strategy can influence retrieval. In the notebook chunking-strategies.ipynb, we take the Microsoft Build 2024 Book of News PDF document and chunk it in various ways for retrieval. My original use case was to get up to speed on the announcements made at Microsoft Build by using a generative AI bot to comb through the document and extract relevant information.
Please note, you will need an Azure Document Intelligence, Azure Search, as well as an Azure OpenAI instance to run the notebooks.
In the notebook, we employ the three chunking strategies discussed earlier. Take a look at the Book of News document in the repo, and take note of the structure. For my use case, I wanted to pull all the ‘Azure AI Announcements’ (e.g., section 1.1) from the Build document. Let’s run through the chunking strategies to see which one is best for summarizing the Azure AI Announcements in the Book of News.
Character Splitting
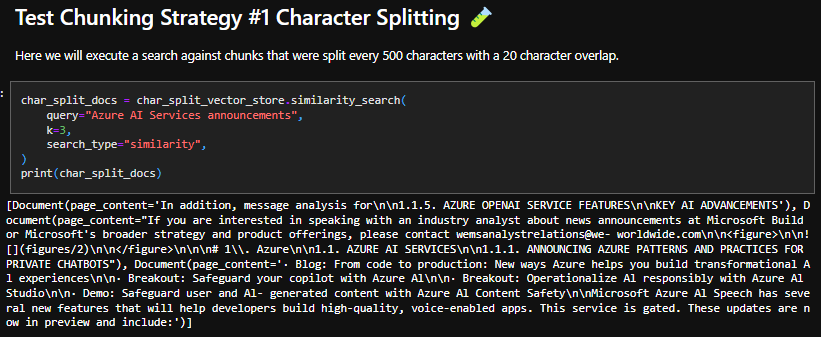
The results here are not great. From the chunks upserted into Azure Search, only 2 out of 9 Azure AI Services Announcements were retrieved, which is insufficient. This outcome makes sense since character splitting is the most basic form of chunking and does not consider document structure.
Header and Recursive Character Splitting
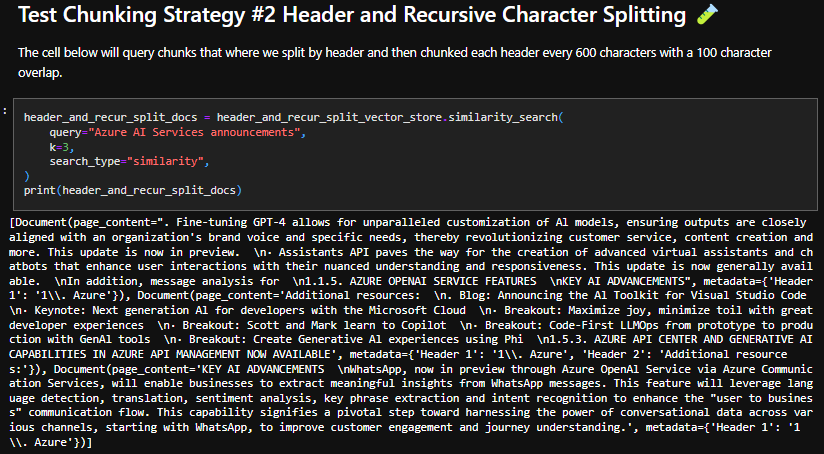
The results here are suboptimal, with only one mention of an AI announcement (1.1.5 AZURE OPENAI SERVICE FEATURES). Recursive character splitting can work well in the right scenario, but in this case, it appears to yield worse results compared to character splitting.
Header Splitting
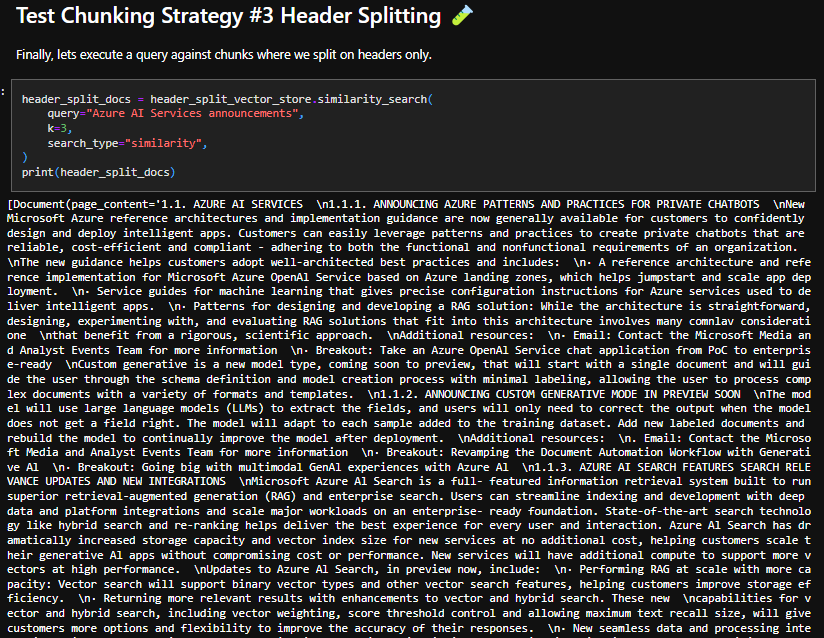
By splitting on headers (document-specific chunking), we achieved better results, retrieving an exhaustive list of AI announcements. All 9 announcements were included in the retrieved text:
1.1.1. Announcing Azure Patterns and Practices for Private Chatbots
1.1.2. Announcing Custom Generative Mode in Preview Soon
1.1.3. Azure AI Search Features Search Relevance Updates and New Integrations
1.1.4. Azure AI Studio Lets Developers Responsibly Build and Deploy Custom Copilots
1.1.5. Azure OpenAI Service Features Key AI Advancements
1.1.6. Khan Academy and Microsoft Announce Partnership
1.1.7. Microsoft Adds Multimodal Phi-3 Model Phi-3-Vision
1.1.8. Safeguard Copilots with New Azure AI Content Safety Capabilities
1.1.9. Speech Analytics, Video Dubbing in Preview in Azure AI Speech
This demonstrates that header splitting is the optimal chunking strategy for our use case. The retrieved information can be used to enhance the LLM’s dataset, with the quality of responses being heavily influenced by the retrieved data. Proper chunking enables efficient retrieval of semantically similar chunks and reduces the signal-to-noise ratio in the prompt.
Conclusion 🏁
Do not neglect the data preparation work in your RAG pipeline. As Greg Kamradt aptly said, “Do not chunk for chunking’s sake; the goal is to get our data into a format that can be retrieved for value later.” The way you chunk your data will have a significant impact on retrieval, which is the first step in your RAG pipeline and influences all subsequent steps. Always consider the types of questions users will ask, the structure of the document(s), and how the retrieved results will be used. This thoughtful approach will set up your RAG pipeline for success.
Thank you for reading.