
Azure AI Content Understanding 🤖

In my previous blog, I explored Azure AI Vision and its capability to support semantic search on videos. Videos (e.g., MOV, MP4, M4A, 3GP, etc.) are just one type of content we encounter in data engineering and generative AI workflows. In the past, I have taken advantage of LangChains many document loaders to process various content types like PDFs and CSVs. While these work well for textual data, they often fall short when dealing with audio or video content.
Enter, Azure AI Content Understanding, a new service that promises to simplify reasoning over large volumes of unstructured data. Its pitch is intriguing: a unified platform for processing diverse content types that accelerates insights by producing structured outputs ready for automation and analysis.
In this post, I’ll dive into what this service offers, explore its potential applications, and see how it stacks up against tools I’ve used in the past.
What Is Azure AI Content Understanding 🤷♂️
As the documentation mentions, ‘Content Understanding offers a streamlined process to reason over large amounts of unstructured data’. What does that mean exactly? One of the significant challenges in scaling Retrieval-Augmented Generation (RAG) applications is feeding trustworthy, structured data into the pipeline. Especially when the source content spans diverse formats like videos, audio, and documents. Azure AI Content Understanding appears to target this exact problem by unifying the process across all content types.
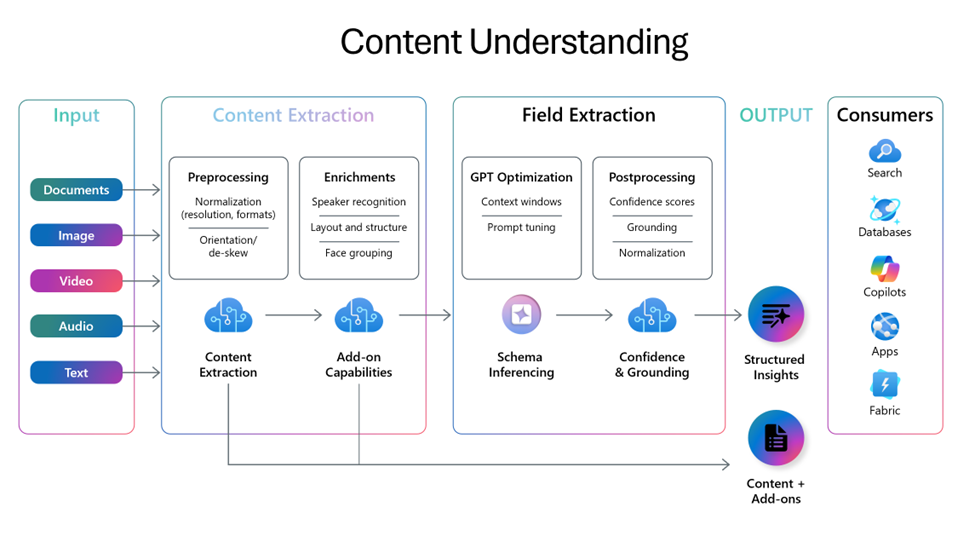
One tool I have used in the past, specifically for textual content types like PDFs is the Structured output from OpenAI.
I really liked this approach since I can specify a pydantic class that can be passed to the LLM to help inform it what fields to extract from a document.
In the documentation, they specify a pydantic class like so to extract the name, date, and participants from a document. That is then passed to a parameter called response_format to help instruct the LLM on how to output the data.
class CalendarEvent(BaseModel):
name: str
date: str
participants: list[str]
completion = client.beta.chat.completions.parse(
model="MODEL_DEPLOYMENT_NAME",
messages=[
{"role": "system", "content": "Extract the event information."},
{"role": "user", "content": "Alice and Bob are going to a science fair on Friday."},
],
response_format=CalendarEvent,
)
The LLM will output the data in a JSON format. This is great from a consumption standpoint since JSON is very easy to parse.
{
"content": {
"name": "Science Fair",
"date": "Friday",
"participants": ["Alice", "Bob"]
}
}
This approach works beautifully for textual content but becomes less practical for formats like video or audio. That’s where Content Understanding shines. It extends structured extraction to more complex content types like video.
For instance, you can define a schema for video analysis:
"fieldSchema": {
"fields": {
"Description": {
"type": "string",
"description": "Detailed summary of the video segment, focusing on product characteristics, lighting, and color palette."
},
"Sentiment": {
"type": "string",
"method": "classify",
"enum": ["Positive", "Neutral", "Negative"]
}
}
}
In the Content Understanding documentation it talks about field extraction where it ‘enables the generation of structured data for each segment of the video, such as tags, categories, or descriptions, using a customizable schema tailored to your specific needs’. This is pretty powerful as we will see in the subsequent sections.
Let’s have a look at the API to see how we can send content to the service.
Content Understanding API 🧑💻
I have created a notebook to process a video and a PDF document that you can use as a reference.
We can perform many of the operations in Content Understanding via the REST API. To analyze content, we need to follow the below steps:
-
Create a new analyzer. This allows us to specify a schema that describes the structured data we want to extract.
-
Once the API call has been made to create the analyzer, we will check the status via the Analyzers - Get endpoint. This is to ensure the analyzer was created properly.
-
Next, we can pass through a file/content (ie: video/pdf) to the Analyze API. Note similar to Azure AI Vision, the file/content must be stored in a blob storage account and a SAS token must be generated so Content Understanding can read that file.
-
And finally, we can see the results via the Get Result API. The data will be returned to us in a nice JSON format, making it very easy to parse for downstream tasks.
Combining all these steps into a notebook allows us to automate this process across many files. To demonstrate what the JSON response looks like in step 4, I have sent a video through an analyzer and got the following results (note, I have truncated the results for demonstration purposes):
{
"id": "807b3cc7-cf03-4967-ad25-0ca53ed39ba3",
"status": "Succeeded",
"result": {
"analyzerId": "video-analyzer",
"apiVersion": "2024-12-01-preview",
"createdAt": "2025-01-14T21:17:44Z",
"warnings": [],
"contents": [
{
"markdown": "# Shot 0:0.0 => 0:0.67\n## Transcript\n```\nWEBVTT\n\n```\n## Key Frames\n- 0:0.0 ",
"fields": {
"sentiment": {
"type": "string",
"valueString": "Neutral"
},
"description": {
"type": "string",
"valueString": "The segment starts with a completely black screen, likely indicating the beginning of the video before the actual content starts."
}
},
"kind": "audioVisual",
"startTimeMs": 0,
"endTimeMs": 67,
"width": 640,
"height": 360
},
{
"markdown": "# Shot 0:0.67 => 0:4.204\n## Transcript\n```\nWEBVTT\n\n```\n## Key Frames\n- 0:0.67 \n- 0:1.68 \n- 0:2.69 \n- 0:3.70 \n- 0:4.71 ",
"fields": {
"sentiment": {
"type": "string",
"valueString": "Positive"
},
"description": {
"type": "string",
"valueString": "This segment features a group of horses running along a beach. The scene is vibrant with the blue ocean and sky providing a picturesque background. The lighting is natural, highlighting the motion and energy of the horses. The overall atmosphere is dynamic and lively, capturing the beauty of nature."
}
},
"kind": "audioVisual",
"startTimeMs": 67,
"endTimeMs": 4204,
"width": 640,
"height": 360
}
]
}
}
You will notice a few interesting key/value pairs in the JSON data. In the contents array, you can see a JSON object for each ‘segment’ in the video with the timestamps noted in the markdown field.
Based on the documentation, it seems Content Understanding identified segments in a video via something called ‘key frame extraction’. It appears Content Understanding abstracts this and ‘extracts key frames from videos to represent each shot completely’.
Definitely a bit of a black box (for better or worse) to make this all work and it makes me curious how well (or not) Content Understanding will perform on larger more complex videos. It is unclear to me exactly how the service groups frames from a video together for analysis.
Also, in the ‘fields’ object you can see the two fields we defined in our schema when we created the analyzer (ie: description and sentiment) which could be used for things like RAG to retrieve information from those fields.
Integrating an LLM for RAG 🤖
Let’s hack out a basic RAG flow to test how this data can be used by an LLM. We are going to leverage the following libraries to get going:
-
langchain-chroma which enables LangChain and ChromaDB integration. Chroma is an open-source vector database that I leverage often to quickly mock applications that require backing by a vector database.
-
langchain_openai enables LangChain and Azure OpenAI integration. We will need to leverage ada-002 to vectorize the data returned from Content Understanding and gpt4o-mini to generate a response based on the users question and data retireved from Chroma.
At a high-level, this is what we will build:
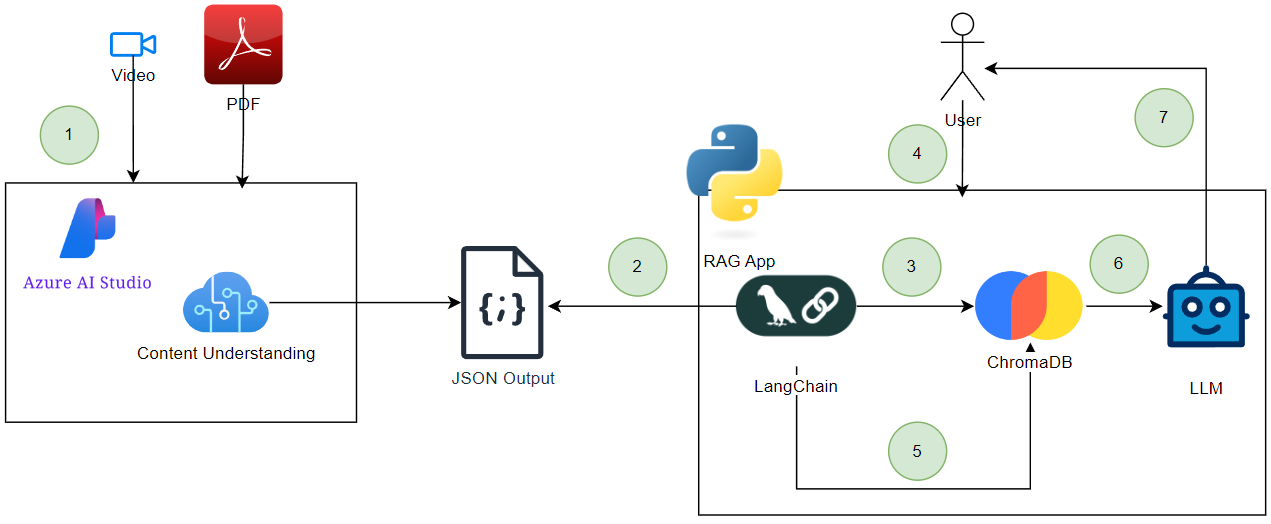
-
Get our sample PDF and video into Content Understanding.
-
RAG app reads and parses the JSON output from the analysis of each of the files.
-
RAG app transforms and upserts the data into ChromaDB.
-
User passes through natural language query to the RAG app.
-
RAG app takes the query and passes it through to ChromaDB to perform a semantic search.
-
Results are taken and passed to an LLM.
-
A response is provided back to the user.
Running the notebook end-to-end runs steps 1-7 and allows us to ask questions on the video and PDF. The video captures animals in the wild and the PDF contains the Content Understanding documentation.
You will notice at the bottom of the notebook; I ask two questions. The first question I ask is ‘What part in the video shows a sleepy animal?’. This question first gets sent to ChromaDB to retrieve the most semantically similar results and then we plug those results into a prompt to an LLM, just like in the diagram above.
In my case, the LLM responded with:
‘The part of the video that shows a sleepy animal occurs between the timestamps 00:20.854 and 00:24.625. During this segment, a sleepy koala is nestled against a tree branch, appearing to yawn or prepare for sleep. The scene is described as having soft lighting, which creates a serene and peaceful atmosphere, complementing the koala’s relaxed posture.’

This is a good response since the 20 second mark of the video does show the yawning Koala.

The next question I asked was “What date was content understanding published?”. The LLM responded with:
‘The content understanding documentation for Azure AI was published on November 19, 2024’.

Having a look at the Content Understanding documentation reveals that is the correct publishing date.
This is neat that we can perform RAG over multiple content types (ie: video and pdf).
I also like the ‘confidence score’ that gets exposed when running a document through Content Understanding. This indicates Content Understandings level of confidence that the data extracted is correct. For example, the ‘Date_Published’ field for the PDF data extraction had a confidence score of 92.4%.
"Date_Published": {
"type": "date",
"valueDate": "2024-11-19",
"spans": [
{
"offset": 119295,
"length": 10
}
],
"confidence": 0.924,
"source": "D(71,1.4697,1.0715,2.2102,1.0715,2.2102,1.2258,1.4697,1.2258)"
}
This is a great feature for downstream automation. You could set a threshold for the confidence score where you do not perform a certain task if it is lower than a specified threshold (ie: <= 80%). If you are exposing extracted data in a PowerBI report, you could expose that confidence score to the end user to give them an idea how reliable the data extracted by Content Understanding is.
Conclusion 🏁
Azure AI Content Understanding has potential as a tool for extracting structured data from unstructured content like PDFs, images, and videos. The ability to define custom schemas and the focus on automation make it an interesting option for those working on RAG solutions or other content-heavy workflows. That said, it’s still early days, and while my initial experiments have been encouraging, there’s room to see how it handles more complex scenarios and larger datasets.
For developers and data engineers, the JSON outputs and API make integration with tools like LangChain or Databricks relatively straightforward. It could become a useful piece in the puzzle for building end-to-end data pipelines or semantic search applications.
Overall, it’s a promising service, but the real test will be how well it scales and adapts to more demanding use cases. If you’re exploring new tools for content extraction, it might be worth trying this out to see if it fits into your workflow. Let me know what you think if you do!