
🎨🧑🎨 The Art of Keeping Things Simple

🚀 Introduction
Mark van der Linden and I wanted to collaborate on a blog called ‘The Art of Keeping Things Simple’ and discuss the challenges with data platforms and how the more popular “modern” reference architecture over complicates an already complicated problem.
Building a data platform is hard enough. Why make it more complicated than it needs to be? Too often, organizations over-engineer their architecture by introducing unnecessary layers of orchestration, duplication, and tooling. The result? A fragile, hard-to-maintain system that slows down development and increases costs.
We all know that managing data is hard:
- Data comes in all shapes and sizes, and we are expected to make it available in a common place.
- The quality of the data is often not well understood, and if we know there are data quality issues, we often ignore it.
- Data Governance is almost always lacking.
We populate our data platforms with data from Oracle, SQL Server, DB2, Excel, TXT, API’s, CSV, Streaming Data etc. Every source has different issues, every API is likely different, excel files always have issues and generally frustrates the hell out of us.
In a recent example we brought in data from a source dataset that looked pretty standard. After profiling the data, we found only 13 of 65 tables had a “row changed date” column, so how do you perform incremental updates? The profiling also showed that there were some future dated records in the row changed date. We discovered that there was a source specific column in each of the tables, the datatype said it was a date field but when we tried to read it, it came back as binary. Again, how can we incrementally get data from these tables?
Why did we detail this one example? Because it’s one of many different sources we need to bring into the lakehouse that required custom coding.
There is no magic bullet for each of these sources and each of these problems. Many companies will introduce individual technologies for sources, Azure Data Factory (ADF) for table data, custom code for API’s and Excel, streaming technologies for streaming data.
Our solution was to take a custom code (Python) based approach to solve these problems, bringing all these various patterns into a single software solution. We apply software development & platform engineering best practices to enable us to deliver quickly.
There is no magic here! 🔮🪄
Through this blog, we’ll take you on a journey of building our solution and share some actionable takeaways along the way. Our goal is to show how simplifying your architecture and focusing on pragmatic, well-tested solutions can help you avoid the trap of over-engineering.
We hope you enjoy this journey with us and find some useful insights for your own work. 😀
NOTE: Within this blog we talk about the standard medallion architecture, being bronze, silver and gold. We have adopted different names which are landing, raw, enriched, product and enterprise which makes more sense for our business but for the sake of clarity in this blog, we have kept to bronze, silver and gold.
📊🤯 Data is Complicated
Data is complicated! Why further complicate things with technology?
A common reference architecture is using Azure Data Factory (ADF) to orchestrate Databricks. Many teams default to this pattern, believing it’s the “best practice” simply because ADF is Microsoft’s go-to orchestration tool. But does it really add value? Do low code tools such as ADF really make data platforms easier to build and operate?
Don’t get us wrong, do we think ADF has a time and place? Yes, but as we discuss throughout the blog, we detail an alternative approach that helps accelerate delivery and make your platform more maintainable.
The biggest question we need to ask, and one that we often forget about is “What business problem are we trying to solve?”
- Does the business care that we use Azure Data Factory to get the data into the bronze layer? Probably not.
- Does the business care about the latency of the enterprise data? Most likely yes.
- Does the business ever need to connect directly to the bronze data in the data lake? Maybe yes but rarely.
- Does the business want consistent and timely access to accurate data? YES!
These are the questions we would like you to ask yourself while reading this post.
🏭 The Traditional Approach: ADF + Relational Metadata Store
The common pattern Microsoft mentions in many of their reference architectures for big data analytics looks something like this:
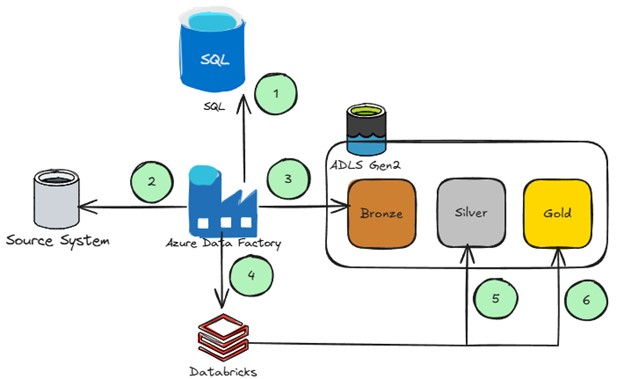
- Data factory ties into a relational database (generally SQL) where pipelines, triggers, and linked services are defined.
- Data Factory orchestrates the data extraction from a source.
- Data Factory copies the data from source into the bronze layer.
- Data Factory calls databricks notebooks to orchestrate the rest of the flow.
- Databricks (via notebooks) moves data from bronze to silver generally converting the data to delta.
- Databricks then moves the data from silver to gold potentially performing N number of transformations to model the data.
Microsoft also details this approach in their metadata-driven approach for ADF documentation where all of your data engineering objects (ie: pipelines, triggers, linked services) are stored in a relational database. While this approach works, we’re not the biggest fans of ETL frameworks that use a relational database to manage objects like pipelines, schedules, and logs.
Managing job definitions, schedules, and execution history in a relational database introduces limitations. It adds complexity, creates a central point of failure, and makes version control more difficult.
🏗️ Building the Platform
We often look at the big tech companies for best practices on building a cloud data platform, the problem is the big companies don’t have insights into your company, and they often don’t have to maintain the solution that is built. But you do. Once you have your platform architecture planned ask yourself this simple question. When we have a problem with the enterprise data (gold) how will I find the issue? Notice that we said, “When we have a problem” and not “If we have a problem”.
If your architecture is like the one in the ‘The Traditional Approach: ADF + Relational Metadata Store’ section, to troubleshoot a potential problem in an enterprise report, you might have to:
- Review your report to see if the data is refreshed.
- Review the data in gold if the problem is there. You will need to review the logs and scheduling.
- Review the data in the silver layer to see if the problem is there. You will need to review the logs and scheduling.
- Review the data in the bronze layer to see if the problem is there. You will need to review the logs and scheduling.
- Review the source dataset.
As you can see there are far too many hops, too many places to check, too many technologies where configurations, security, networking and logs that need to be reviewed.
As mentioned earlier, we propose a simplified architecture where Databricks orchestrates the full stack. This approach is a custom code (Python) based approach:
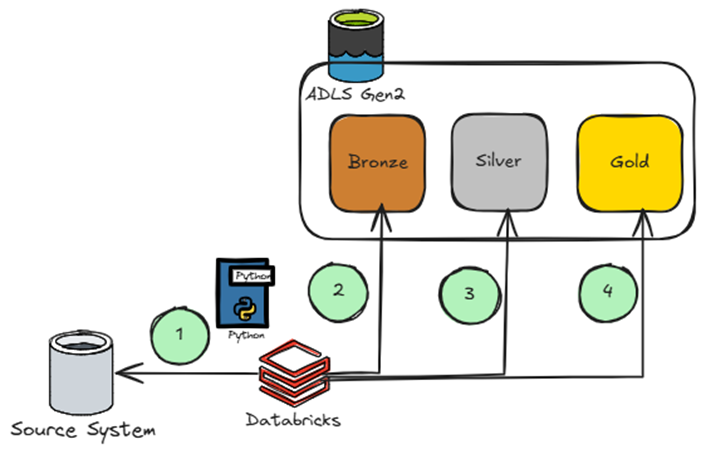
As discussed later in this blog, applying good platform and software engineer concepts is critical to taking this approach, otherwise, the code base can become nonmaintainable very quickly.
In the commonly proposed architecture where ADF calls Databricks, ADF acts as an orchestrator for Databricks and is effectively calling notebooks in Databricks, which contain code. We are not sure this is a necessary step especially since Databricks has lots of great existing orchestration functionality called workflows which has really helped orchestrate our notebooks including scheduling and sequencing notebooks.
Also, the ADF integration with Databricks does not support some of the newer Databricks offerings like serverless compute. This is a huge miss in our opinion since serverless compute has faster start times and generally cheaper costs compared to interactive clusters. Leveraging ADF railroads us into waiting for the product team to add support for new Databricks features and functionality.
The big advantage ADF provides is its integration runtime and its ability to interact with data sources that may exist behind your corporate firewall. The integration runtime is a virtual machine that has ‘line of sight’ to your on-premises sources from a networking standpoint. The great part about this is the integration runtime only takes up one IP address (generally) versus if you are doing something like what we are doing in Databricks such as pulling data from on-premise systems behind the firewall, many more IP addresses are required to allow the cluster to do this. This is a challenge we had to overcome and had to work with the cloud and networking teams to get CIDR blocks large enough to accommodate the size that Databricks clusters can grow to. Thankfully, Databricks publishes some great guidance on this in their ‘Deploy Azure Databricks in your Azure virtual network (VNet injection)’ documentation which helped guide our conversations with the cloud/networking teams.
The common counter point to approaching this complex world with a custom code approach is, ‘we are not a software development shop’. However, most organizations would be surprised to know how much code they do have, especially moving from silver to gold due to the potential complexity of the transformations. If you follow the ADF and Databricks integration architecture, ADF is often calling lots of custom code anyways in the form of Databricks notebooks. We would argue that Python is a commodity skill set with lots of great talent in the industry. Leveraging generative AI coding assistants like the ones that are offered in Databricks, further lowers the barrier to entry making training and onboarding much easier.
📊🛠️🔍 Applying Platform & Software Engineering Practices to Data
Since we are taking a custom code approach to data engineering, we have had to consider the impacts of that decision and have heavily leaned on traditional software development practices to make adding to and maintaining the solution much easier and have also turned to more modern platform engineering practices as well.
Platform engineering is a practice built up from DevOps principles that seeks to improve each development team’s security, compliance, costs, and time-to-business value through improved developer experiences and self-service within a secure, governed framework. It’s both product-based mindset shift and a set of tools and systems to support it.
By applying platform engineering principles to data engineering, we ensure that data pipelines, platforms, and analytics workflows are developed systematically, efficiently, and with high quality. As data is constantly evolving, integrating these best practices helps maintain reliability, scalability, and governance. A “code-first” approach with proper platform engineering simplifies processes, making data engineering workflows more scalable and maintainable.
We defined a few goals that we are striving for on our data platform:
- Have three or fewer active branches in the application’s code repository.
- Merge branches to trunk at least once a day.
- Don’t have code freezes and don’t have integration phases.
- Average code review time per PR less than 30 min.
Meeting these goals equates to faster releases and generally faster time to value for our customers/business.
Below are the various processes and practices that have been working well for us. It has enabled us to ship new features quickly while ensuring existing functionality remains functional and we are not introducing bugs into the code base.
🧑💻 Code Standards: Writing Maintainable Data Pipelines
We’ve been following an object-oriented approach while building out our data pipelines. This has allowed us to encapsulate many of the components and make them extremely reusable. Here is the high-level architecture of our software. There are two key components, ETLJob and GenAIJob, each of which have their own ‘readers’, ‘transforms’ and ‘writers’ enabling us to very quickly ingest, transform and serve data from a variety of sources:
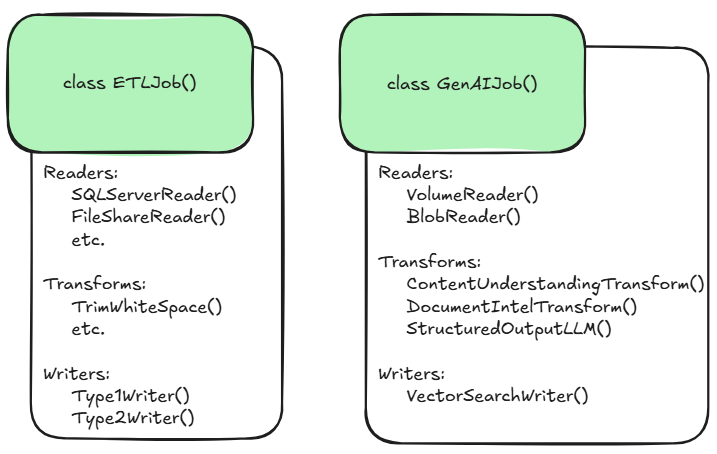
Both ETLJob and GenAIJob classes have reusable components (defined as classes) that developers can leverage for a multitude of tasks such as:
- Brining data into the platform.
- Applying a transform to a dataset.
- Measuring data quality on a dataset.
- Integrating LLMs and vector databases.
At a high-level, you can specify one reader, multiple transforms, and multiple writers all through a JSON configuration file.
To help make sense of how these components are used, lets step through a few quick examples/use cases.
Ingest From SQL
Let’s say we want to bring in data from a SQL source into our lake and drop the files into bronze and then silver. We can tie into existing functions in ETLJob to do this and we can define all this in a JSON file:
source_to_bronze_to_silver = {
"Read": {
"SQLServerReader": {
"connection": "SQLB",
"primary_keys": ["pk"],
"schema_name": "schema",
"table_name": "table",
"query": "SELECT * FROM table",
},
},
"Write": {
"ParquetWriter": {
"connection": "lake",
"file_path": "lake_path",
},
"Type1Writer": {
"connection": " lake ",
"write_type": "merge",
"primary_keys": ["pk"],
"catalog_name": "unity_catalog_name",
"schema_name": " unity_catalog_schema_name",
"table_name": "table",
},
},
}
Following an object-oriented approach allows these components to be reusable and enabled data engineers to chain together multiple transforms and writers. In this case, the JSON file leverages the SQLServerReader to read tables from SQL. The ParquetWriter to write the tables from SQL as parquet in bronze and the Type1Writer to write the detla tables as SCD Type 1.
Structure Unstructured PDF’s
We’re also tackling use cases that require generative AI functionality. It made sense to make those components reusable too. Just like the ETLJob framework, we have a GenAIJob framework that enables data engineers to string together multiple transformations and writes. In the example below, we process PDF documents stored in a Unity Catalog volume, running them through our document intelligence transform that integrates with Azure Document Intelligence for OCR and chunking. Next, we can process these OCR chunks through the StructuredOutputLLM transform, where based on a list of fields in a PyDantic class, we can extract structured data.
ingest_pdfs = {
"Read": {
"VolumeReader": {
"catalog_name": “catalog_name”
"schema_name": "schema_name",
"volume_name": "volume_name",
},
},
"Transform": {
"DocumentIntelligenceTransform": {
"output_volume_name": "volume_name”,
"mode": "single, markdown or page",
"doc_intelligence_secret_scope": "secret_scope_name",
"doc_intelligence_api_key_secret_name": "api_key",
"doc_intelligence_endpoint": "endpoint
},
"StructuredOutputLLM": {
"model_name": “llm_of_choice,
"prompt_template": “prompt template”,
"pydantic_class": "Pydantic Class",
"output_volume_name": "volume_name”,
}
}
}
We have had a few similar use cases come our way and making the code reusable has accelerated our delivery capabilities.
Novel Transformations
If a data engineer needs to perform a ‘novel’ transformation (i.e., a transformation that isn’t included in ETLJob or GenAIJob), they can easily add extra code to their notebook. If it’s a transformation that could be reused, the data engineer can add it to the framework.
The key takeaway is that we’re never limited by our framework. “One-off” scenarios can be easily accommodated. For example, a custom transformation can be inserted into your GenAIJob or ETLJob run.
def main():
try:
# call our JSON config file
ingest_pdfs = GenAIJob(ingest_pdfs)
ingest_pdfs.runAll()
# custom transformation logic
except Exception as e:
s = f"An exception was thrown: {e}"
slogger.warning(s)
raise Exception(s)
if __name__ == "__main__":
main()
🧑🔬 Platform Engineering Practices: Making our Releases Efficient
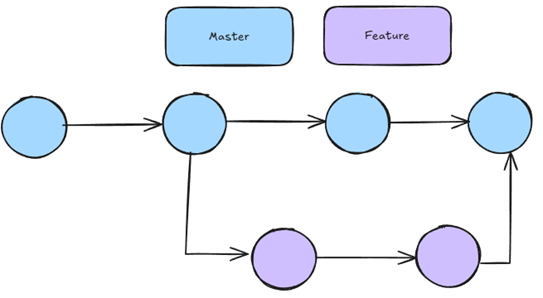
🌴 Branching
We follow a standard ‘feature branching’ strategy. This allows us to meet our goal of reducing the number of active branches (ie: three or fewer). If we merge our branches to master once per day, we run into little issues around things like merge conflicts.
🧑💻 CI/CD
The CI/CD process helps us achieve our other goals around not having code freezes and keeping PR’s less than 30 minutes. We have written unit tests for all the major components of our code base and these unit tests run when a developer opens a PR. There are two conditions that must pass to be allowed to merge your code into main:
- One person must approve the PR.
- The unit tests must have passed.
Also baked into our pipeline are things like linters to make sure developers are following Python best practices. Our CI/CD pipelines look something like this:
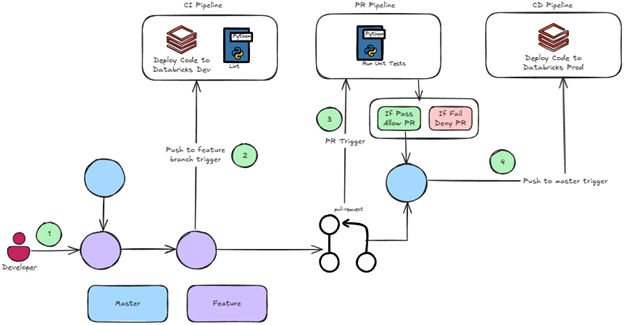
- A developer will create a feature branch off main.
- Each time the developer checks in code to their feature branch, a CI pipeline runs that deploys their workflow to dev and lint’s their code early to let them know of any variable naming convention violations for example.
- When the developer is ready to get their code into production, they open a PR which will automatically kick off our unit tests.
- If the unit tests pass, the feature branch can be merged into main, and another pipeline kicks off to deploy the artifacts to production.
To ensure deployments remain fully version-controlled and repeatable, we leverage Databricks Asset Bundles (DAB). This allows us to define job configurations as YAML, avoiding reliance on a relational database to manage job definitions, schedules, and execution history. Instead of storing metadata in an RDBMS, which adds complexity and limits version control, our monorepo based approach ensures every change is tracked, reviewed, and easily reversible.
🧪 Unit/Integration Testing
Unit and integration testing play a critical role in maintaining the reliability and correctness of our data platform. Since data engineering workflows often involve complex transformations and integrations, having a robust set of tests ensures that changes do not introduce regressions.
We take a mock-driven approach to unit testing, focusing on isolating individual components rather than relying on external dependencies. This allows us to validate transformations, data quality checks, and orchestration logic without needing live database connections or third-party services.
In addition to unit tests, we incorporate integration tests to verify end-to-end workflows, ensuring that data flows correctly between systems. These tests validate interactions with external systems like databases, APIs, and message queues, catching issues that may not surface in unit tests. To make integration tests reliable, we use test containers, sandbox environments, or pre-configured test data to minimize dependency on live systems.
Automated unit and integration testing give us peace of mind when deploying changes, providing confidence that existing functionality remains intact while ensuring our data platform operates as expected in real-world scenarios.
While ADF is starting to support things like unit testing things like this are notoriously difficult to do in low code/’drag and drop’ tools.
🎉 Conclusion
In this post, we’ve explored the challenges of modern data platforms and the unintended complexity that many architectures introduce. While tools like Azure Data Factory have their place, they often add unnecessary orchestration layers that slow down development and increase maintenance overhead. Instead, we’ve argued for a streamlined, software-engineering-first approach leveraging Python, Databricks, and platform/software engineering best practices to build scalable, testable, and maintainable data platforms.
By treating data engineering like a software discipline, teams can move faster, reduce operational complexity, and deliver value to the business with fewer bottlenecks. A well-structured, code-driven approach not only accelerates data delivery but also ensures long-term reliability and flexibility.
By no means is this product perfect, and we are continuously working to improve it. That’s the fun part of our jobs! To give insight into what’s next, we wanted to highlight some short-term improvements and features we are working on.
One key improvement is packaging the software so developers can easily install a specific version using pip install from our internal package repository. This approach ensures better version control, allowing teams to track and manage dependencies more effectively. It also simplifies deployment, reducing friction in onboarding new developers and integrating the software into various environments. By packaging the software, we aim to enhance maintainability, streamline updates, and ultimately provide a more reliable and scalable experience for our users.
We are also building a user-interface that will allow users of our platform to easily see what tables are available and provide them the ability to select the tables they want loaded. Similar to Amazon Prime where you order a package and it arrives the next day, we will ‘deliver’ the table(s) to the user the next day for them to leverage.
So before adding yet another orchestration layer, ask yourself: Is this truly solving a business problem, or are we just making things harder for ourselves?
What’s been your experience with simplifying complex data architectures? We’d love to hear your thoughts in the comments!
Thanks for reading!