
Databricks Vector Search 🧱🔎

The generative AI landscape is quickly getting complicated. There are so many different LLMs that are coming out along with vector databases and an endless number of integrations you need to establish to get a competent generative AI application working.
There are a lot of vector databases on the market right now but one that has really impressed me has been Databricks Mosaic AI Vector Search.
In this blog, I want to get into the reasons why I find this vector database impressive and how to get started with it.
Let’s dive in!
What is a Vector Database 🤷♂️
Before jumping in to how to integrate with Databricks vector search, I wanted to briefly cover what a vector database is along with the problems it solves.
On the surface, a vector database indexes and stores vector embeddings for fast retrieval and similarity search, with capabilities like CRUD operations, metadata filtering, horizontal scaling, and serverless. But what does that mean exactly?
A vector database is a specialized database designed to store, search, and manage data that’s represented as vectors. Here’s what that means in simple terms:
What are vectors?
A vector is just a list of numbers that represents something, like an image, a piece of text, or audio. These numbers capture the essence or features of the data in a way that a computer can understand.
For example:
-
A sentence like “I love apples” might be converted into a vector like [0.8, 0.1, 0.3].
-
Another sentence like “I adore oranges” might be [0.7, 0.2, 0.3].
These numbers are usually created using AI models.
What’s special about vector databases?
-
Similarity search: The database can find items that are similar to a given vector. For example, if you store vectors for images of cats, it can quickly find other cat images that are most similar to a new image.
-
Fast querying: It’s optimized to handle these vector searches efficiently, even when there are millions or billions of vectors.
-
Handling high-dimensional data: Vectors often have hundreds or thousands of numbers (dimensions), and a vector database is built to manage this complexity.
Why use it?
-
If you want to build a recommendation system, like suggesting movies or products similar to what a user likes.
-
To support AI-powered search, like retrieving documents similar to a user’s query.
-
For applications like image recognition, fraud detection, or natural language processing.
Think of a vector database as a super-smart filing system that knows how to group, compare, and retrieve data based on meaning or similarity rather than just keywords or IDs.
I think Databricks does a good job capturing the flow of getting your documents into a vector database:
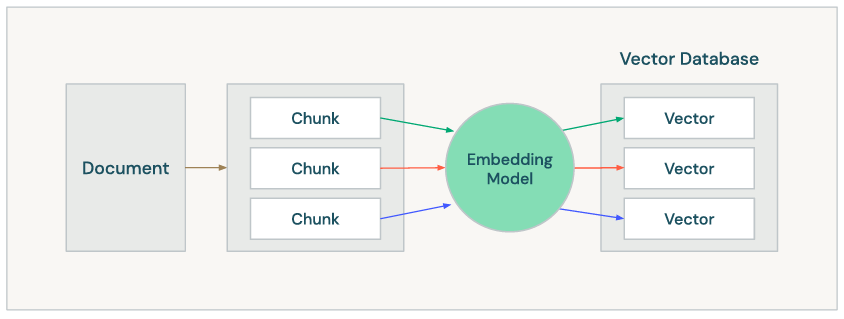
At a high-level we take our document(s) and we go through several stages to prepare the document(s) for upserting into a vector database.
-
The first step is to chunk the document(s), which means breaking the document into smaller, logical chunks that can be upserted into the vector database and will later influence retrieval. To get an idea of how much your chunking can influence retrieval, have a look at my previous blog Chunking for RAG.
-
Next, we need to embed the chunks so we can upsert them into the vector database. An embedding model is a type of language model designed to transform text into a numerical representation known as an embedding, which is a vector of numbers. These embeddings capture the subtle, context-dependent meaning of the text in a mathematical form. For instance, a well-designed embedding model can recognize that the phrase “breaking the ice” refers to starting a conversation, not to physically cracking ice.
-
And finally we can upsert those vectors into the database. Like mentioned earlier, this will enable things like similarity search and support a generative AI powered chatbot that can retrieve documents.
That is vector databases in a nutshell. Let’s now talk about the different types of vector databases in Databricks.
Types of Databricks Vector Databases 🔢
In Databricks there are two types of vector databases:
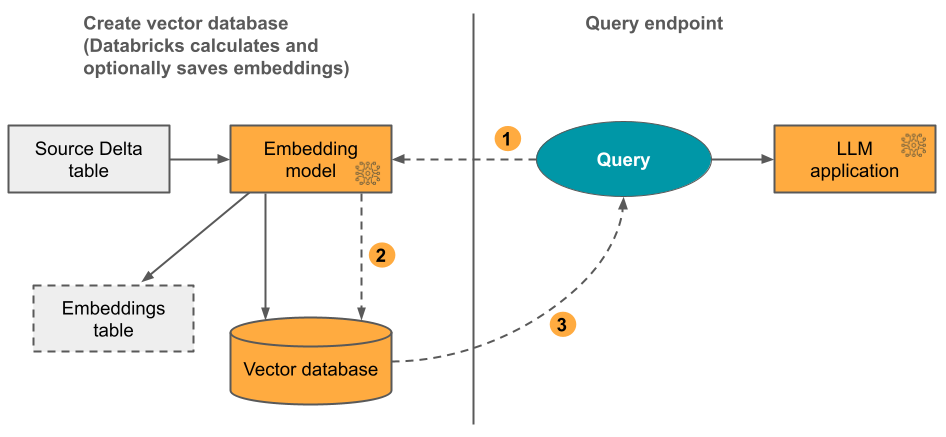
- Delta Sync Index: you can create an index on top of a delta table in Unity Catalog. This option automatically syncs with a source Delta Table, automatically and incrementally updating the index as the underlying data in the Delta Table changes. Below is a diagram from the Databricks documentation that shows how it works:
-
Calculate query embeddings. Query can include metadata filters.
-
Perform similarity search to identify most relevant documents.
-
Return the most relevant documents and append them to the query.
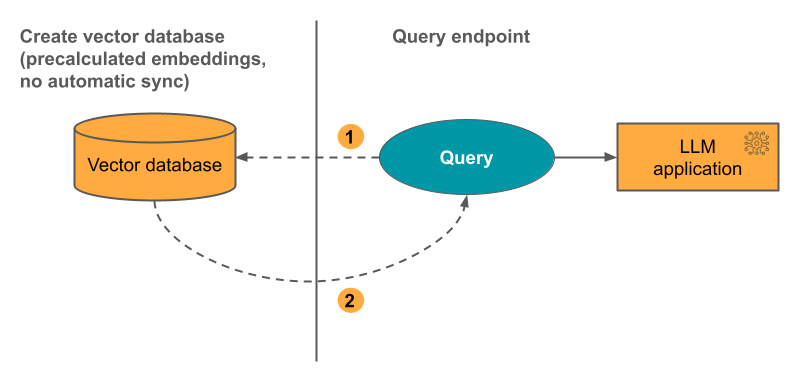
- Direct Vector Access Index: This option is a bit more complicated and supports direct read and write of vectors and metadata. The developer is responsible for updating this. Here is a diagram from the Databricks documentation to articulate how it works:
-
User can query the vector database and return relevant results. Metadata filters can be added.
-
Relevant documents returned to the users.
In this blog, we will deploy both. The first option (ie: Delta Sync) is one of the reasons why I have been impressed by the vector search offering in Databricks. Like I said in my Chunking for RAG blog ‘While everyone is eager for the exciting machine learning and data science aspects, the crucial data engineering work often gets neglected’. This is no different in the GenAI space. The way I see it, if you have spent the time to get your data into a delta table and exposed via Unity Catalog, you have probably (hopefully!) given some thought to how the data looks and as a side effect, your RAG pipeline will work much better.
With the tight integration between the vector database and Unity Catalog, some very powerful workflows are unlocked, especially given the source delta table is automatically synced with the index. To kick things off, let’s start by creating a direct vector access index.
Prepping Databricks Direct Vector Access Index 🧱
Jumping into Databricks, let’s prep everything we need to get going with their vector database offering. If we navigate to the compute tab we can create an endpoint:
Clicking the create button brings up a screen where you can give the vector database a name. I called mine very creatively ‘vector-db’. It will take a few minutes to provision, but eventually you will see something like this:

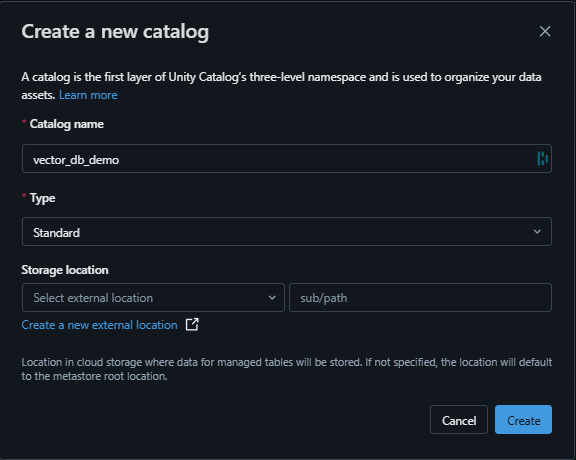
We also need a catalog created since ‘Vector search indexes appear in and are governed by Unity Catalog’. For this example, I have called the catalog ‘vector_db_demo’:
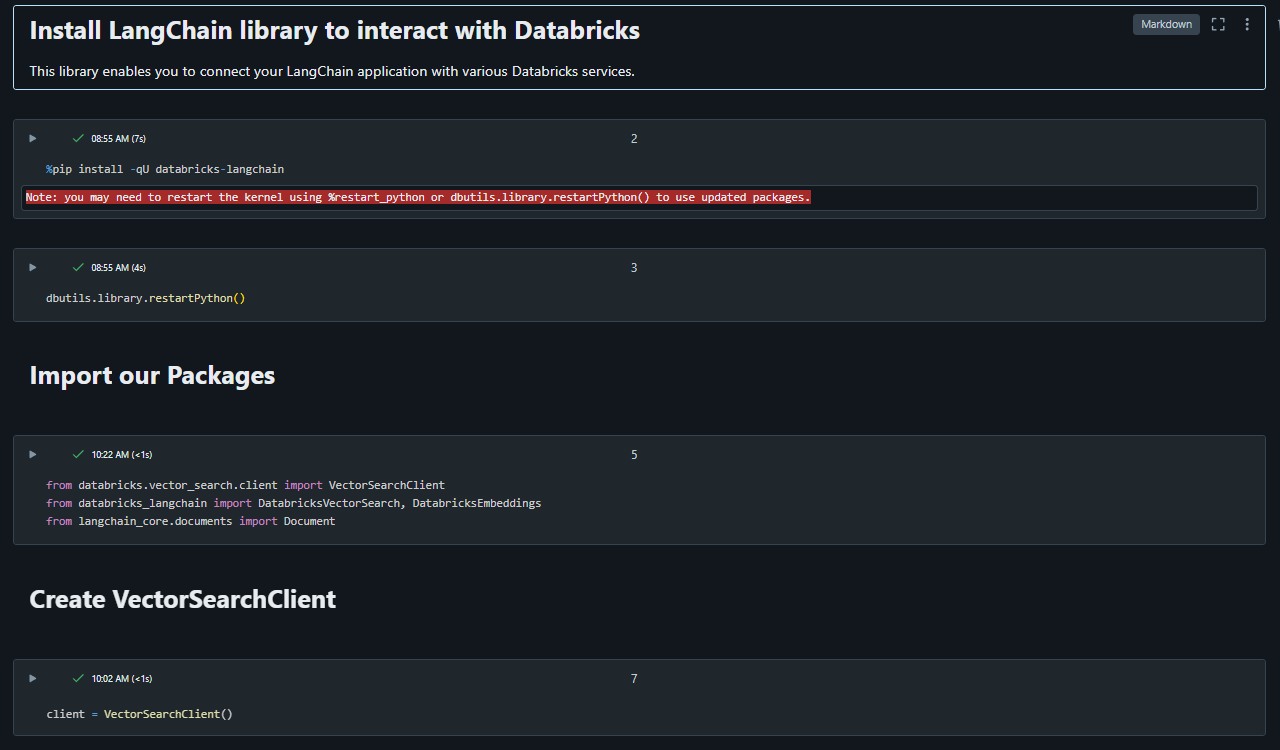
Next, let’s jump over to a notebook and download the required libraries as well as initialize our connection to the vector database. We will start by installing the databricks-langchain library to help us connect and interact with the Databricks vector search. LangChain is a great library to prototype applications very quickly and helps abstract (for better or worse) a lot of the complexities away from the developer. This LangChain/Databricks integration is great to get going. Here is what the notebook looks like so far:
Next we need to create the Direct Vector Access Index leveraging the LangChain abstraction create_direct_access_index(). This abstraction accepts the following parameters:
-
endpoint_name: Specifies the endpoint where the index will be created.
-
index_name: Provides a unique name for the index.
-
primary_key: Identifies the primary key for the index, ensuring uniqueness of entries.
-
embedding_dimension: Defines the size of the embedding vector used for indexing and retrieval.
-
embedding_vector_column: Names the column where embedding vectors are stored.
-
schema: A dictionary representing the structure and metadata of the index.
-
embedding_model_endpoint_name (optional): Specifies an embedding model endpoint to enhance query capabilities with embeddings.
Here are the values we have passed through to each of the parameters to create the index:
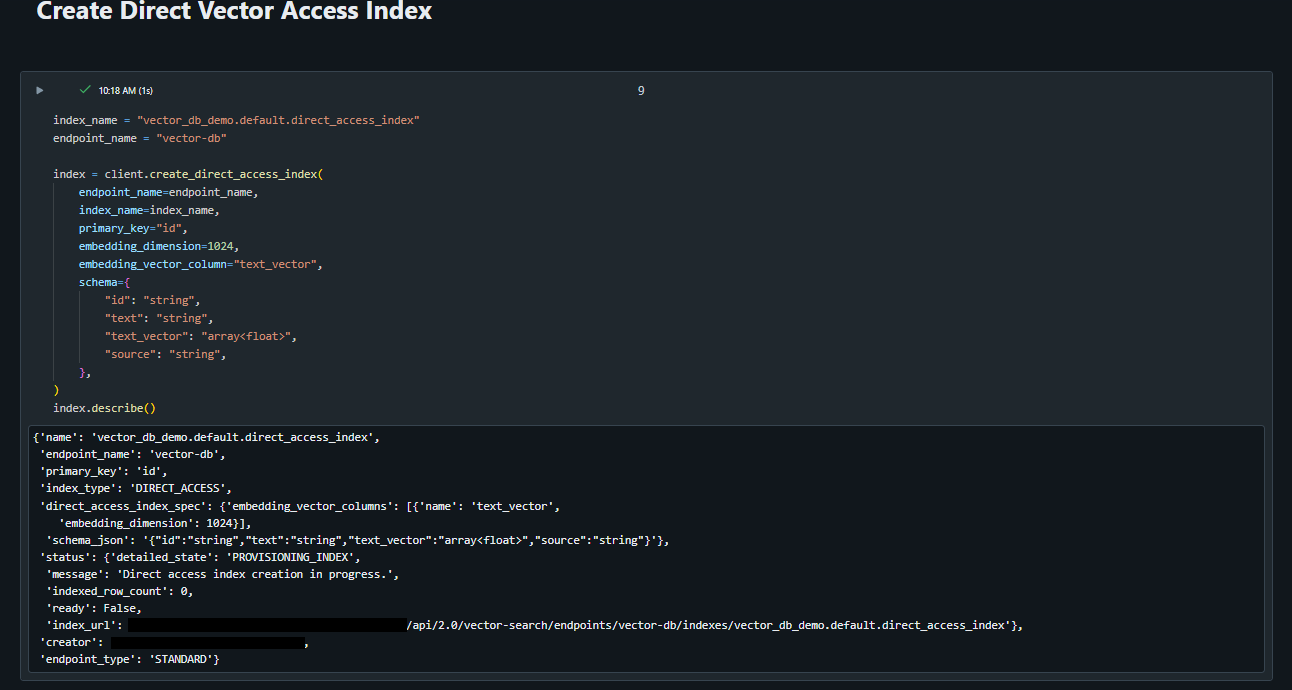
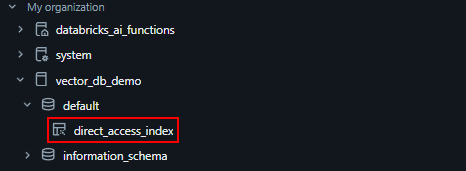
After running this, you will notice an index is created in the previously created catalog.
Since we are leveraging direct vector access, we also need to specify an embeddings model to leverage to generate vectors as mentioned earlier in the blog. In this example, I am leveraging the databricks-gte-large-en model. Here is another great example of why I find these generative AI offerings in databricks so impressive. All of this (ie: vector database, LLM’s, etc.) are all tightly integrated with the platform. In this case, all authentication is being handled through my user account (ie: PAT) which is not great for production workloads, but is very handy for testing since I do not need to worry about passing and storing auth tokens (API keys, credentials etc.)!
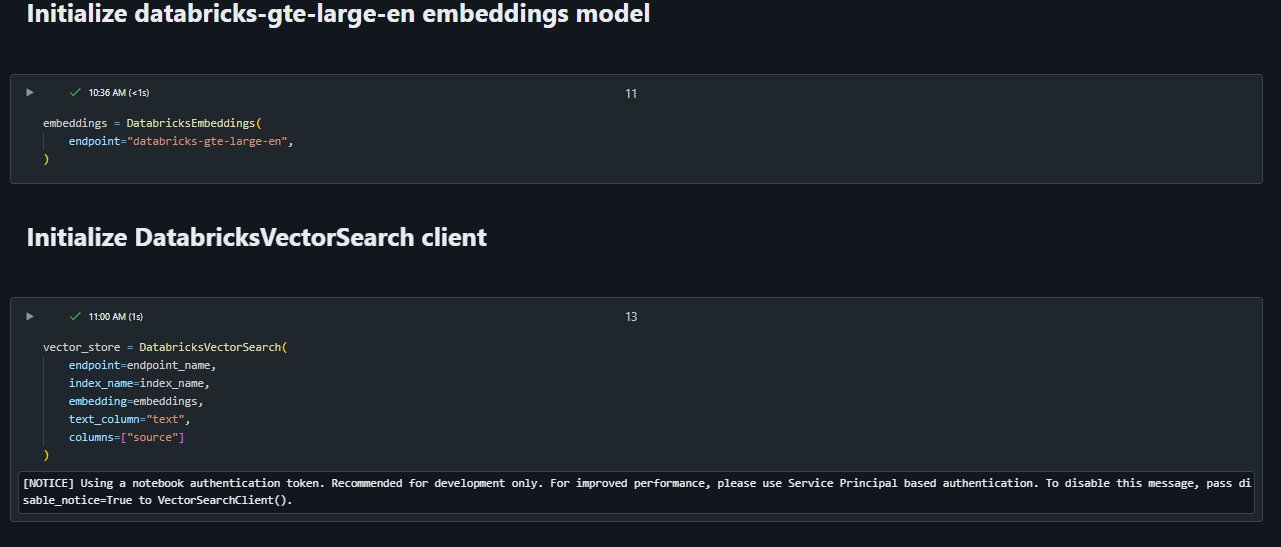
The last step in the prep is to upsert documents to the index. In this case we will leverage the LangChain Document class. The document class in LangChain helps ‘standardize’ the inputs/outputs to/from various LangChain integrations, especially with vector databases.
In this sample, I have copied some headers and text from the Databricks Vector Search Docs to upsert into the vector database. Each ‘Document’ serves as a chunk to be upserted into the vector database.
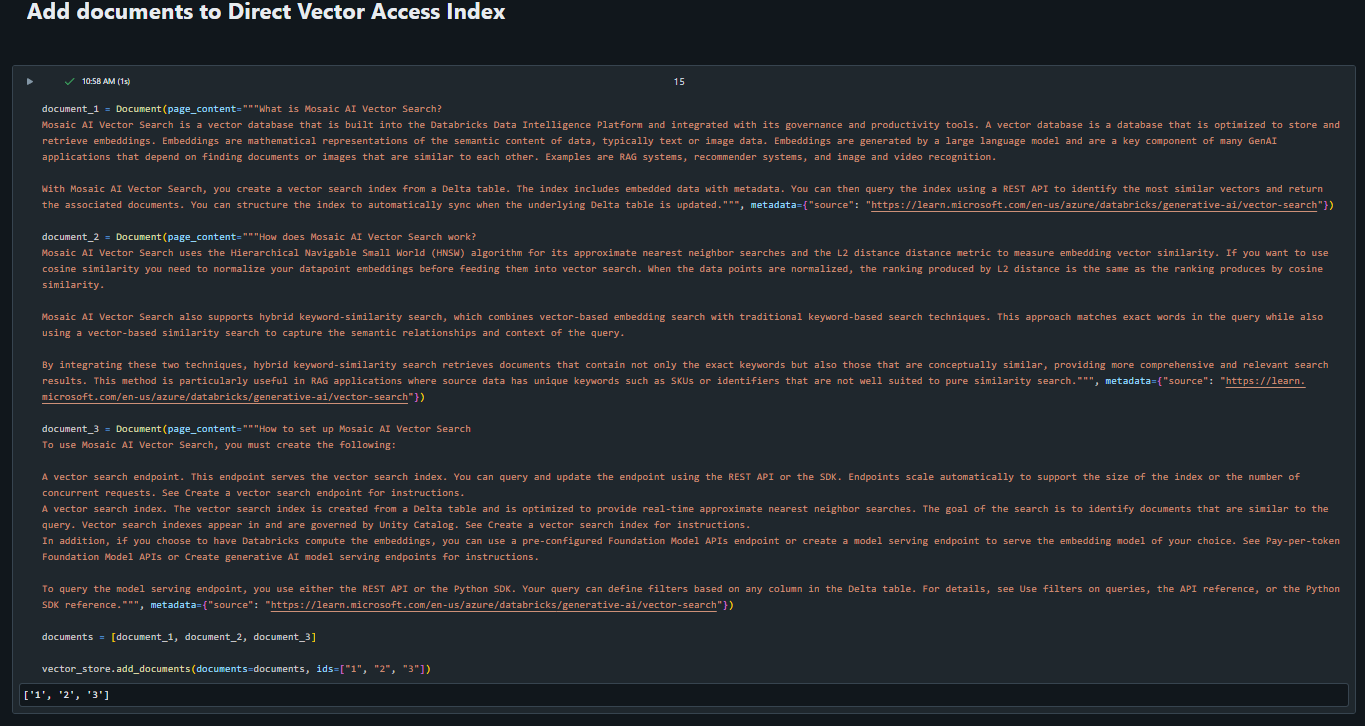
Now that we have upserted some sample data, lets query it.
Querying Databricks Direct Vector Access Index 🔎
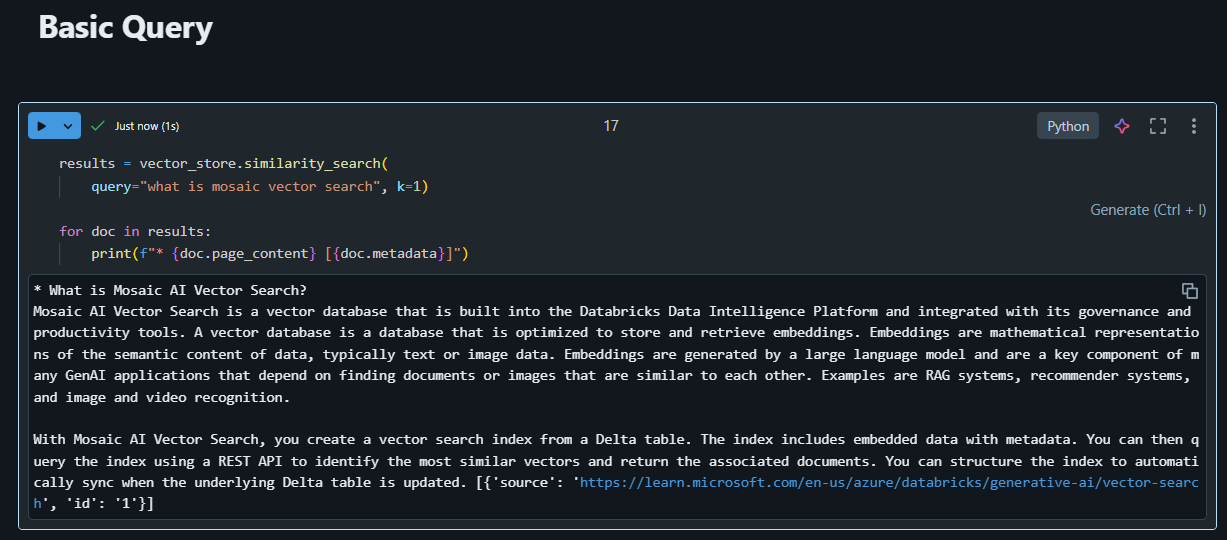
We can now craft a query back to the direct vector access database. In the below example, I leverage the similarity_search() function and pass through the query “what is mosaic vector search” and the number of documents to return using the k param:
We can also pass through a filter using the ‘filter’ param:
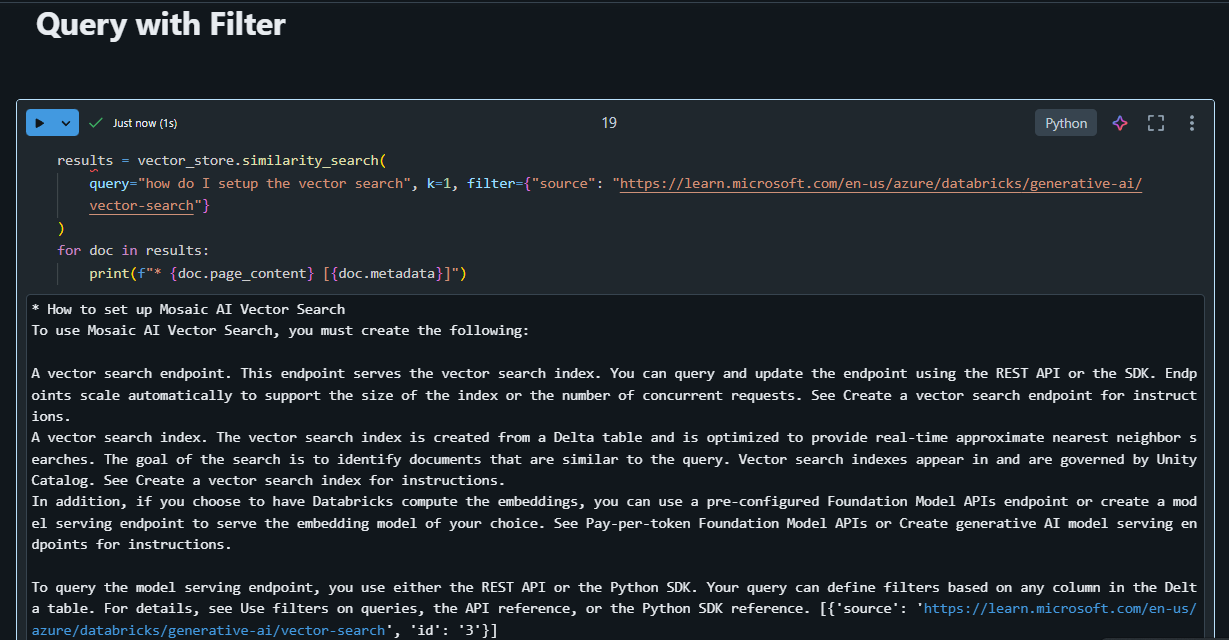
These retrieved results could be passed to an LLM prompt to ‘augment’ the dataset of the model in a RAG pipeline.
Now that we have explored the direct vector access index, lets take a look at the delta sync index.
Prepping Databricks Delta Sync Index 🧱
To prepare for this, I have download the 2020 Yellow Taxi Trip Data and got it into a table exposed in Unity Catalog. To do this, I loaded the CSV into a volume and ran the following commands in Databricks:
# Bring in monotonically_increasing_id to increment SurrogateKey column
from pyspark.sql.functions import monotonically_increasing_id
# Read CSV from volume into data frame
df = spark.read.csv("/Volumes/vector_db_demo/default/taxi_data/2020_Yellow_Taxi_Trip_Data.csv", header=True, inferSchema=True)
# Generate surrogate key and limit to 10 results
df_with_surrogate_key = df.withColumn("SurrogateKey", monotonically_increasing_id()).limit(10)
# Write the data frame to Unity Catalog
df_with_surrogate_key.write.format("delta").mode("overwrite").saveAsTable("vector_db_demo.default.taxi_data").write.format("delta").mode("overwrite").saveAsTable("vector_db_demo.default.taxi_data")
# Enable CDC so the index can be auto updated
%sql
ALTER TABLE `vector_db_demo`.`default`.`taxi_data` SET TBLPROPERTIES (delta.enableChangeDataFeed = true)
Now that the table is loaded into Unity Catalog, we can create a delta sync index:
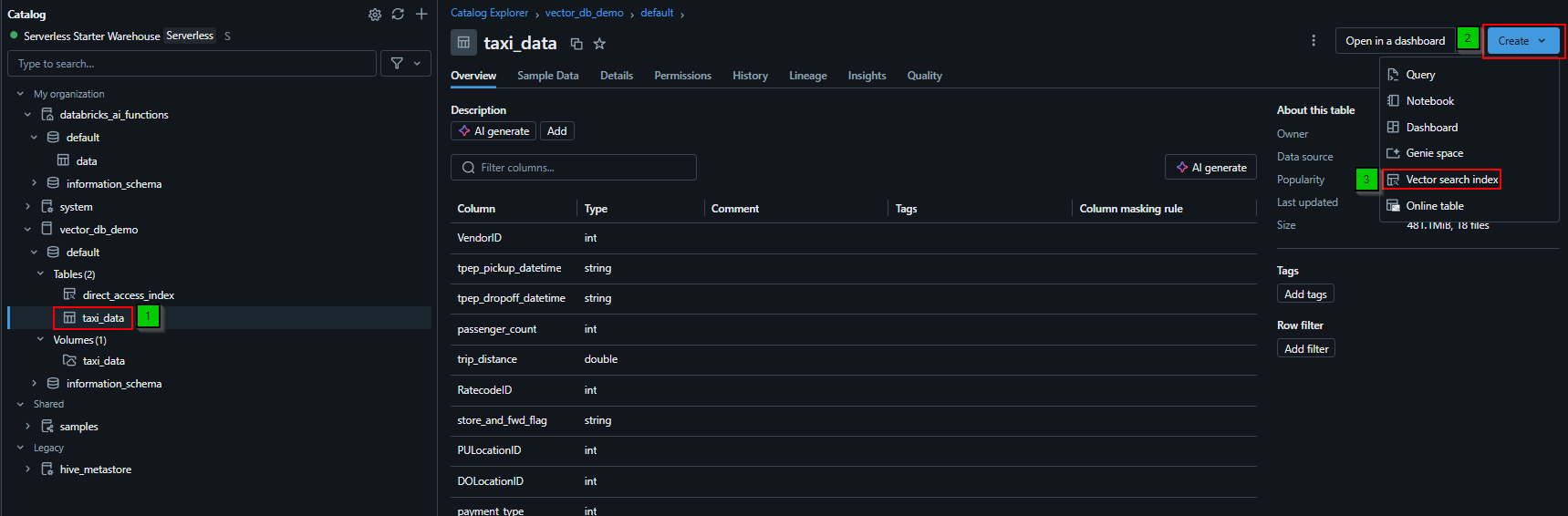
Clicking this will open a menu as follows:
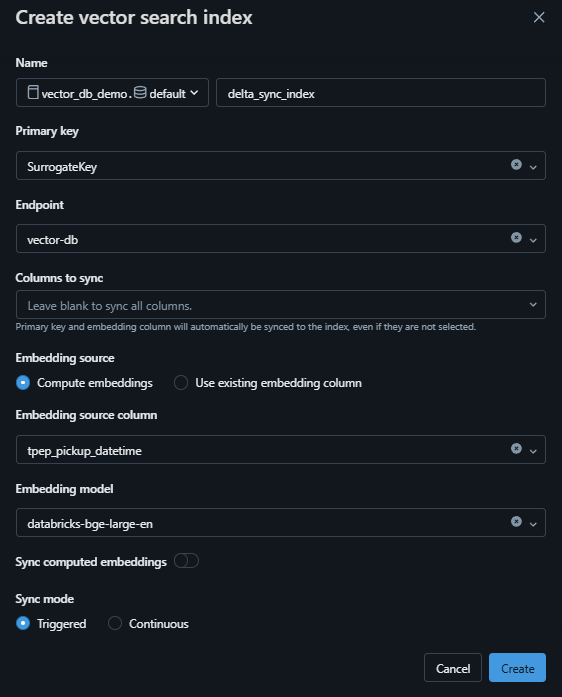
After clicking create, you will notice that a Delta Live Table job is spun up to populate the vector index if you click the below highlighted link, very cool!
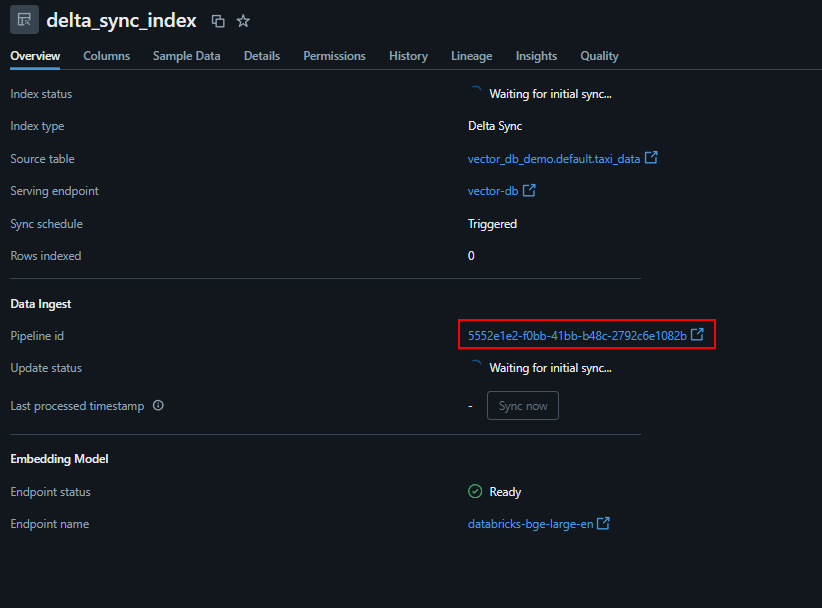
Now that the taxi data is synced we can query this vector database.
Querying Databricks Delta Sync Index 🔎
Similar to direct vector access example, we must initialize our Databricks vector search:
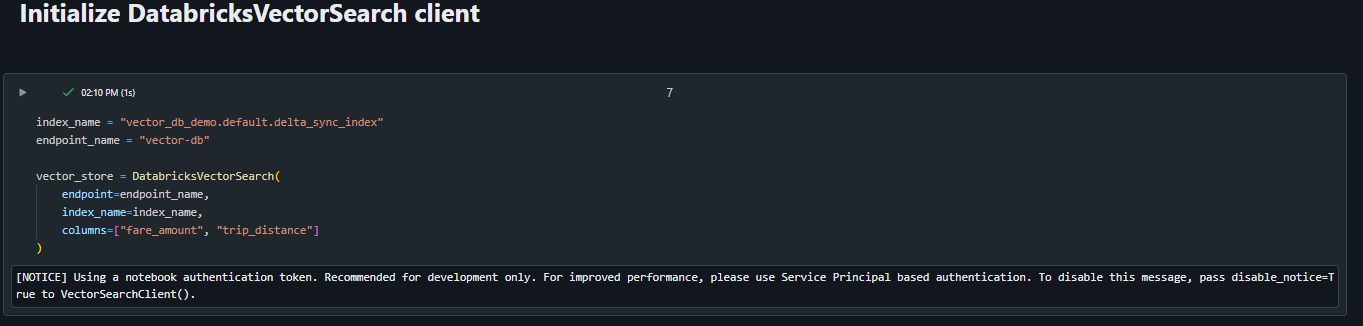
Note, we provide a list of column names to retrieve when doing the search. In this case, fare_amount and trip_distance.
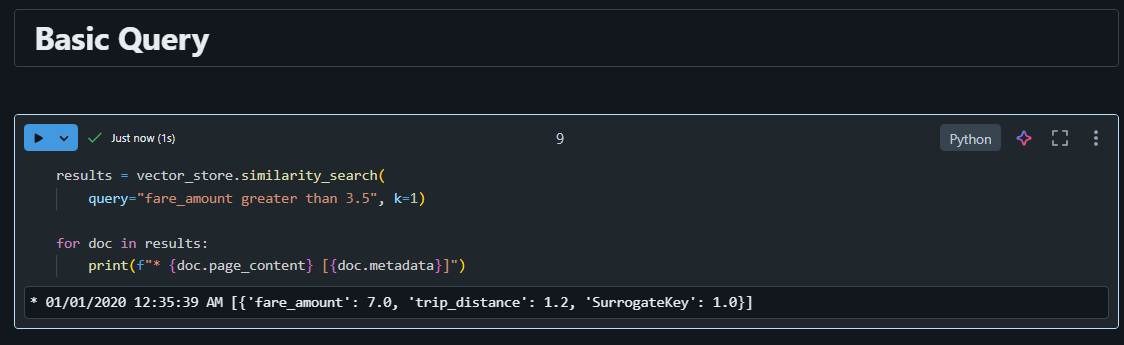
Now we can pass a query to our delta sync enabled index:
Conclusion 🏁
I hope this has provided a good overview on vector databases, specifically in the context of Databricks. Having these Mosaic GenAI offerings tightly integrated into the Databricks platform makes developing these types of applications much easier. Databricks is quickly becoming a ‘one stop shop’ tool that I can leverage for my data engineering, GenAI, and ML needs.
Building RAG type applications is difficult and spending time on integration challenges does not allow you to focus on the value add work. The Databricks platform removes a lot of those integration headaches and allows you to focus on the value add development work!
I have open-sourced the notebooks to interact with the vector database:
Thanks for reading 🙂