
🧱 Building Data Products with Databricks Apps

I have been leveraging Databricks Apps for a few use cases and have been really excited at the potential of this technology. This excitement has inspired this blog post. In the evolving landscape of data engineering, one of the most exciting movements is the rise of data products, curated, reusable, and discoverable datasets and services that teams can consume like any other product. With the introduction of Databricks Apps, building and managing data products is easier, more scalable, and more collaborative than ever before.
Let’s dive in to a blog on how Databricks Apps is helping accelerate development and deployment of our data products.
TL;DR Databricks Apps streamlines the development and deployment of secure, governed data products. This post walks through how we used it to build a RAG app for engineering documentation with minimal Platform Engineering friction.
🧠 What Are Data Products?
Think of data products like APIs, but for data. Instead of exposing raw datasets in a data lake, teams can now publish cleaned, governed, and versioned data assets with defined interfaces and guarantees. These products can be used across teams, departments, and even business units.
Key attributes of data products:
- Discoverable via a catalog or marketplace.
- Trusted with data quality and governance baked in.
- Reusable by different consumers.
- Monitored with built-in observability.
In a recent post called The Art of Keeping Things Simple in Data Platforms, Mark and I talked about how taking a code first approach has allowed us to land data in a fast and standardized way to make consumption downstream much easier.
Now that we have laid many of the foundational data engineering components, brought in data from most of our critical applications, and we can bring in new data with a push of a button, the fun part begins where we can start building out data products to fulfill use cases for our business.
🚀 Enter Databricks Apps
To understand the value Databricks Apps brings to the table, we need to understand what things were like before and the amount of effort required to get these data products into the hands of the business.
We had a recent use case that was effectively RAG (Retrieval-Augmented Generation) on top of training videos. The end users wanted to be able to chat and ask questions on their videos to support certain auditing workflows where auditors may have questions about a certain process or task. This enabled the auditors to search for the information they needed in an efficient way without having them watch potentially hours of content.
To get this application exposed to the end users was a multi-step process and I am still not convinced we got it right:
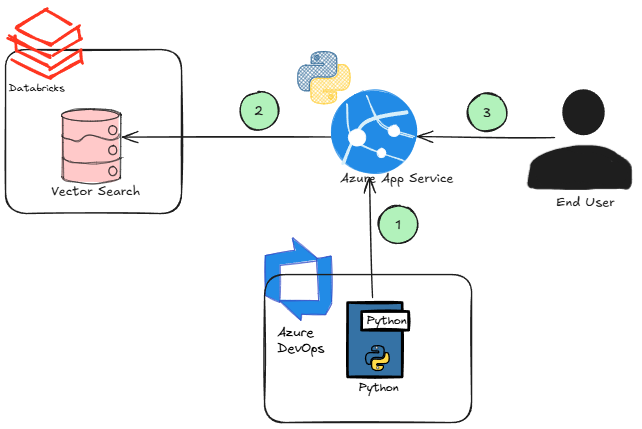
-
The first challenge we faced is we were developing our Python application (ie: streamlit) locally and needed to find a way to push it to the cloud. We decided to go with Azure App Service to host it but now we need to create Terraform scripts to deploy it, secure it behind the firewall, and build a CI/CD pipeline to it to deploy our code.
-
Then we had to start thinking of integrating with Databricks Vector Search. Would we leverage someone’s PAT to authenticate to the vector search? That doesn’t seem very secure. Ideally the app just takes into account the access the user should have and only exposes the objects they have access to.
-
Now the end users can start using it. How will we roll out features quickly? How will we monitor the app?
Deploying the above basically became an ‘integrations problem’ and took us away from quickly providing value to the end users. It took a day or two just to set this up, and that was for a single data product. Of course, we’ll get more efficient over time, but it still adds significant overhead. I would also argue that a handful of steps mentioned above require a platform engineer skillset which most data teams do not readily have access to.
How can we make this process easier for data engineers to allow them to deliver business value faster?
Enter Databricks Apps!
Right from the documentation it says ‘Databricks Apps lets developers create secure data and AI applications on the Databricks platform and share those apps with users’.
But what does that mean?
As we just saw, building products on top of data managed in Databricks is very difficult. It traditionally ‘required deploying separate infrastructure to host applications, ensuring compliance with data governance controls, managing application security, including authentication and authorization, and so forth. With Databricks Apps, Databricks hosts your apps, so you don’t need to configure or deploy additional infrastructure’.
Continuing to follow the above example, this means we can develop, deploy, monitor, and secure our data product all in one platform.
🔧 Databricks Apps Use Case
We recently had another use case come in from engineering where they wanted to perform RAG on top of a set of process documents (ie: PDFs). The use case was for folks on site maintaining the integrity of our pipelines needing to quickly search/index large amounts of documents. Documents meaning both internally developed and external from government regulatory agencies.
A good example is we have developed a ‘Defect Evaluation Standard’ where integrity personnel will reference it when they are assessing ‘in-ditch’ defects like metal loss and dents. This is just one of many documents integrity personnel may need to reference making this use case a potentially good candidate for semantic/keyword search and maybe even layering an LLM on top of it.
I have really struggled building out these RAG architectures as it can be difficult to know what ‘good’ looks like and how to ensure high quality responses. For example, there are many considerations when building these RAG systems out:
- Chunking Strategy: Are we going to use fixed token chunking or semantic chunking?
- Retrieval Strategy: What retrieval strategy will we use? Hybrid? Keyword? Semantic?
- LLM Selection: Is there an LLM better geared towards the use case?
The above list is just to name a few of the challenges with building RAG architectures.
Thankfully, we have some very bright folks on the engineering side with lots of amazing technical backgrounds. We thought leveraging Databricks Apps for this use case would enable collaboration between IT and the engineering team and allow us to actively involve them in the development and testing process.
Because we’ve simplified our approach to building data products, collaborating has become much easier. The full end-to-end process can be done almost entirely in Databricks:
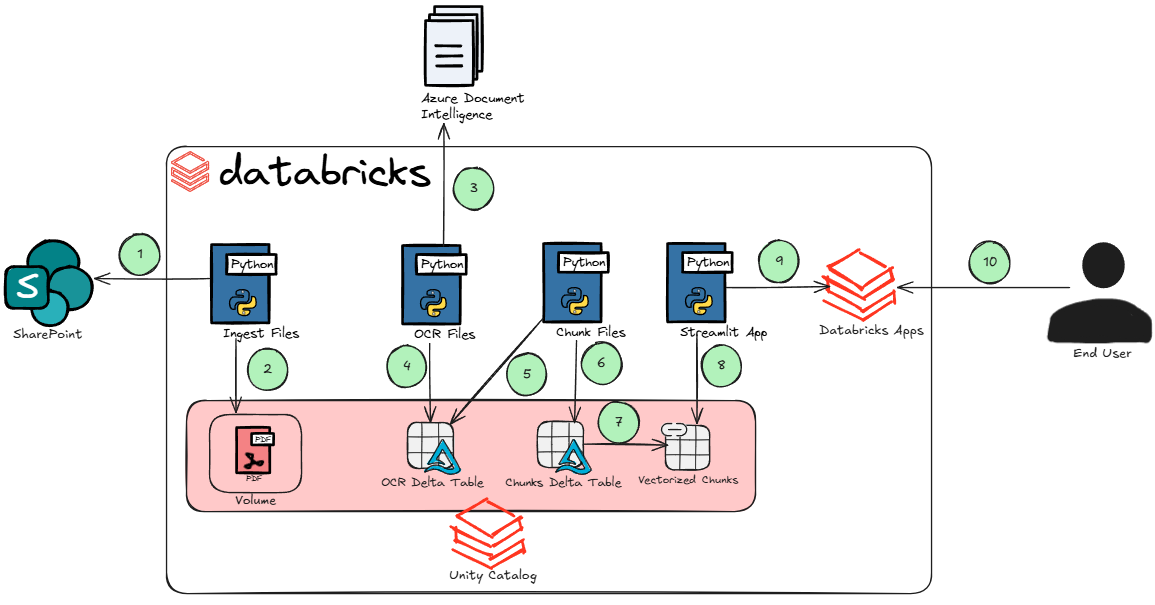
- Download process documents from SharePoint.
- Drop downloaded process documents into a Unity Catalog volume.
- Send process documents to Azure Document Intelligence to be OCR’d. This is the only external service we use outside of Databricks for this app. I am not aware of an OCR model that we can leverage as part of Databricks model serving platform, otherwise, we would likely be using that. We have Document Intelligence output the text in markdown format since many of these process documents contain complex tables.
- Write the OCR markdown to a delta table.
- Since many of these process documents contain too many tokens to embed, we must chunk them. In this step, we read each of the files markdown.
- Write the chunks to a delta table.
- Since Databricks has the option of Delta Sync for vector databases, writing our document chunks to a delta table makes embedding that data very easy. In this step, we embed the chunks.
- This is where our streamlit app comes into play and Databricks Apps really shines. Now that we have a vector database we can perform searches on, we build a streamlit app to call it.
- Deploy the streamlit app to Databricks Apps. To do this is literally the push of a button.
- End users can now test/use the application.
This may seem like more steps then the previous method, however, since we spent the time building a framework around this as discussed in the blog post The Art of Keeping Things Simple in Data Platforms, performing operations like the above becomes very easy. I would also argue this method better aligns with the skillsets of data engineers in comparison to the previous method.
It goes without saying we did not nail the chunking, retrieval, LLM selection, or the look and feel of the app on the first try. We are still working on it in fact. But since this entire process is contained within Databricks, we are easily able to collaborate with engineering and update the underlying delta tables, vector database, test cases, as well as test different retrieval strategies like multi-query retrieval and reranking very easily all based on their feedback.
The point here is there are a lot of moving pieces to successfully deliver data products and being able to roll out changes quickly allows us to solicit feedback from our end users faster.
🤷♂️ What’s Next?
As we continue to iterate on this use case, one important consideration is offline availability. Many of our users will be accessing this application on site, potentially in areas with limited or no internet connectivity. While building everything inside Databricks gives us huge advantages in speed, governance, and collaboration, we’ll likely need to support an offline-friendly version of this app at some point.
That means whatever retrieval strategy or data structure we decide on, whether it’s semantic search, keyword-based retrieval, hybrid approaches, or reranking, it needs to be portable. A few things we’re already thinking about:
- Precomputing embeddings and saving them locally.
- Packaging a small FAISS index that can be queried offline.
- Storing process documents and metadata in a local format like SQLite or DuckDB.
- Shipping a lightweight version of the app in a container that runs on a mobile device or tablet.
This won’t be zero effort, but the good news is that since everything is already chunked, embedded, and versioned in Delta tables, we can map that structure to a local representation without reinventing the wheel.
We’re also actively exploring pass-through authentication to ensure users can only access what they’re entitled to in Unity Catalog. This is critical, we’re not just building apps, we’re building secure, governed data products. If a user doesn’t have permission to view a document/table in Databricks, they shouldn’t see it in the app either.
Databricks has a code sample in their documentation we are looking at implementing in our Streamlit app, ie:
# cfg with auth for Service Principal
sp_cfg = sdk.config.Config()
# request handler
async def query(user, request: gr.Request):
# user's email
email = request.headers.get("X-Forwarded-Email")
# queries the database (or cache) to fetch user session using the SP
user_session = get_user_session(sp_cfg, email)
# user's access token
user_token = request.headers.get("X-Forwarded-Access-Token")
# queries the SQL Warehouse on behalf of the end-user
result = query_warehouse(user_token)
# save stats in user session
save_user_session(sp_cfg, email)
return result
Note From chatting with someone internally at Databricks, Databricks Apps will be available in the Canadian cloud regions very soon! 🍁
Looking ahead, we’ll continue exploring ways to:
- Rapidly prototype and evaluate new retrieval strategies.
- Collect feedback from users in the field to guide future iterations.
- Identify other high-impact use cases where Databricks Apps can help us move from idea to deployment in hours instead of weeks.
We’re still learning and experimenting, but the ability to develop, deploy, and secure our apps all in one place is changing how we build. The future of data products feels a lot more collaborative, and a lot more hands-on.
Thanks for reading 😁!